Q. F. LIU ET AL.
Copyright © 2011 SciRes. AM
730
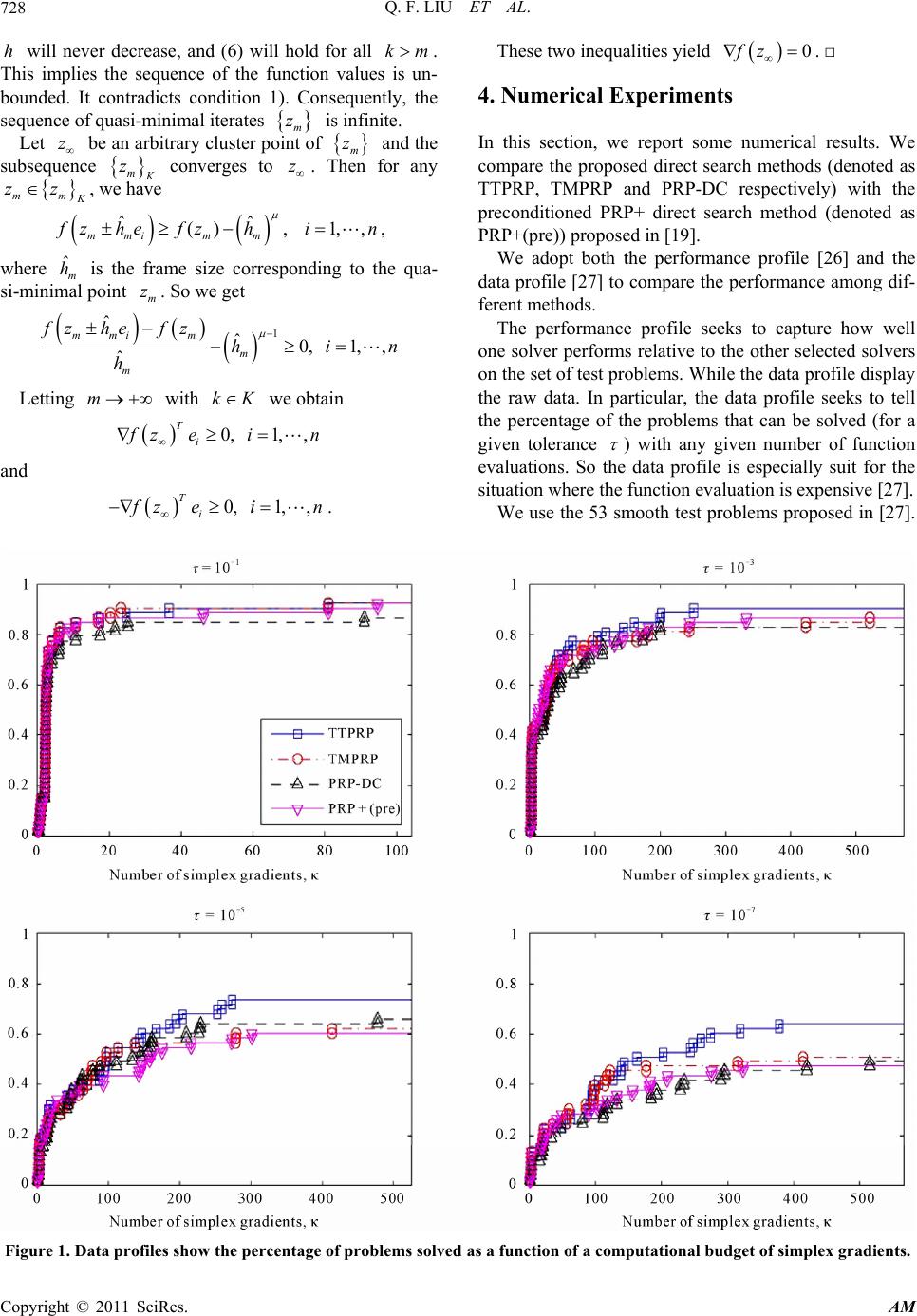
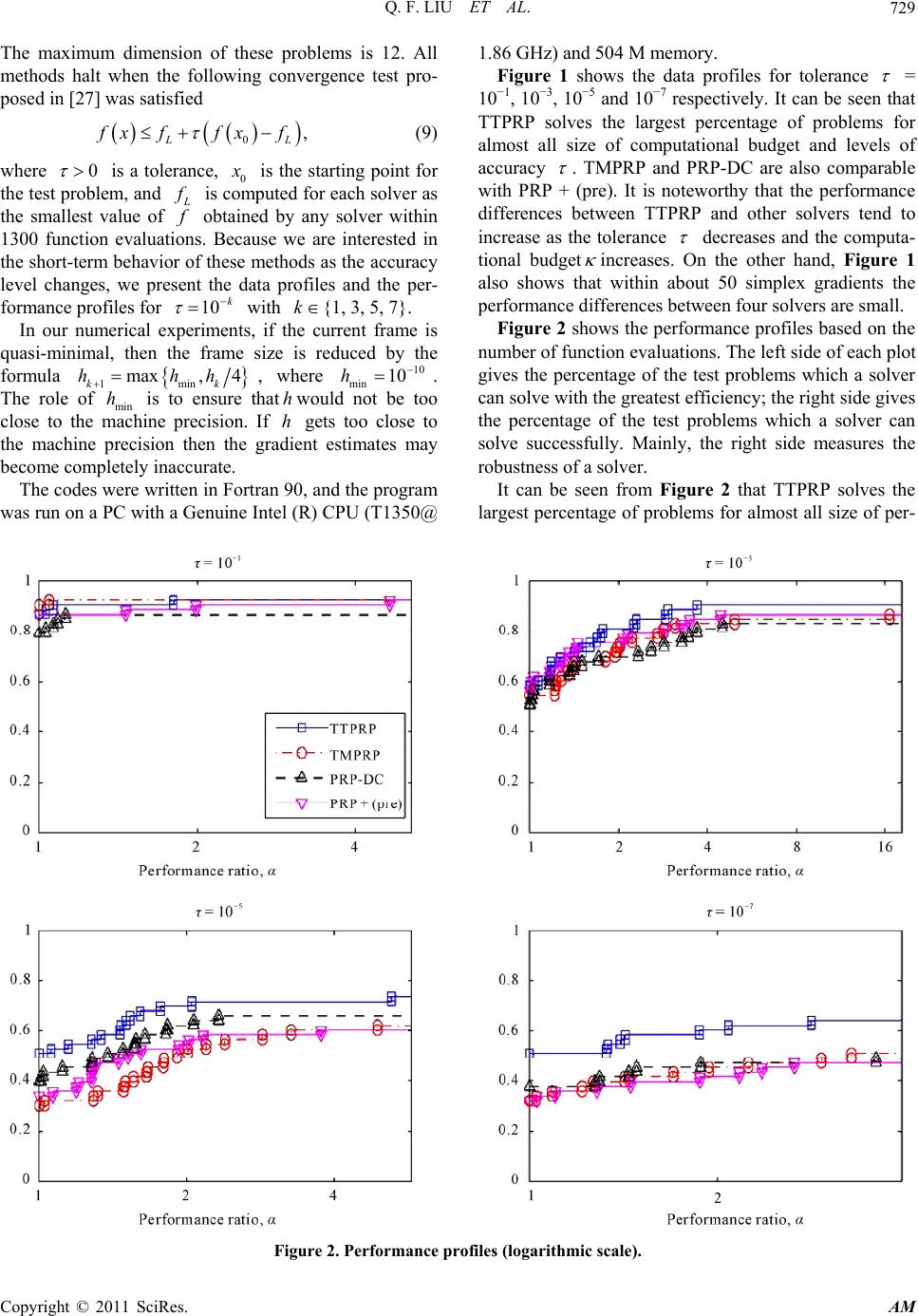
formance ratio and levels of accuracy
. TMPRP and
PRP-DC are also comparable with PRP + (pre). It is
noteworthy that the performance differences between
TTPRP and other solvers still tend to increase as the tol-
erance
decreases.
5. Discussion
Based on the Coope-Price direct search framework, we
proposed three PRP-type direct search methods. All of
them employ a kind of descent conjugate gradient direc-
tion. When exact gradients are available, descent conju-
gate gradient methods can generate sufficient descent
directions for the objective function, and numerical re-
sults have shown that they are often computational more
effective than PRP+ method.
In this paper, the gradient information of the objective
function is not available. We estimate the gradients based
on the function values obtained at the maximal positive
basis. These gradients estimated may be not accurate
very much, but global convergence can be ensured under
the Coope-Price direct search framework. In other words,
convergence is guaranteed by the frame-based nature of
the algorithms, not the fact that they mimic a conjugate
gradients method.
The accuracy of the gradients estimated may also af-
fect the descent property of the descent conjugate gradi-
ent directions. However, the numerical results show that
the proposed PRP-type direct search methods are prom-
ising and competitive, especially the TTPRP method.
6. References
[1] W. C. Davidon, “Variable Metric Method for Minimiza-
tion,” SIAM Journal on Optimization, Vol. 1, No. 1, 1992,
pp. 1-17. doi:10.1137/0801001
[2] R. Hooke and T. A. Jeeves, “Direct Search Solution of
Numerical and Statistical Problems,” Journal of the ACM,
Vol. 8, No. 2, 1961, pp. 212-229.
doi:10.1145/321062.321069
[3] M. J. D. Powell, “Direct Search Algorithms for Optimi-
zation Calculations,” Acta Numerica, Vol. 7, No. 1, 1998,
pp. 287-336. doi:10.1017/S0962492900002841
[4] A. Conn, K. Scheinberg and P. L. Toint, “On the Con-
vergence of Derivative-Free Methods for Unconstrained
Optimization,” In: M. D. Buchmann and A. Iserles, Eds.,
Approximation Theory and Optimization, Cambridge
University Press, Cambridge, 1997.
[5] B. Karasozen, “Survey of Trust-Region Derivative Free
Optimization Methods,” Journal of Industrial and Man-
agement Optimization, Vol. 3, No. 2, 2007, pp. 321-334.
[6] M. J. D. Powell, “A View of Algorithms for Optimization
without Derivatives,” Technical Report DA MT P2007/NA03,
Department of Applied Mathematics and Theoretical
Physics, University of Cambridge, Cambridge, 2007.
[7] R. M. Lewis and V. Torczon, “Rank Ordering and Posi-
tive Bases in Pattern Search Algorithms,” Technical Re-
port 96-71, Institute for Computer Applications in Sci-
ence and Engineering, NASA Langley Research Center,
Hampson, 1996.
[8] V. Torczon, “On the Convergence of the Multidirectional
Search Algorithm,” SIAM Journal on Optimization, Vol.
1, No. 1, 1991, pp. 123-145. doi:10.1137/0801010
[9] V. Torczon, “On the Convergence of Pattern Search Al-
gorithms,” SIAM Journal on Optimization, Vol. 7, No. 1,
1997, pp. 1-25. doi:10.1137/S1052623493250780
[10] R. M. Lewis and V. Torczon, “Pattern Search Algorithms
for Bound Constrained Minimization,” SIAM Journal on
Optimization, Vol. 9, No. 4, 1999, pp. 1082-1099.
doi:10.1137/S1052623496300507
[11] R. M. Lewis and V. Torczon, “Pattern Search Methods
for Linearly Constrained Minimization,” SIAM Journal
on Optimization, Vol. 10, No. 3, 2000, pp. 917-941.
doi:10.1137/S1052623497331373
[12] C. Audet and J. E. Dennis Jr., “Analysis of Generalized
Pattern Searches,” SIAM Journal on Optimization, Vol.
13, No. 3, 2003, pp. 889-903.
doi:10.1137/S1052623400378742
[13] C. Audet and J. E. Dennis Jr., “Mesh Adaptive Direct
Search Algorithms for Constrained Optimization,” SIAM
Journal on Optimization, Vol. 17, No. 1, 2006, pp. 188-
217. doi:10.1137/040603371
[14] I. D. Coope and C. J. Price, “On the Convergence of
Grid-Based Methods for Unconstrained Optimization,”
SIAM Journal on Optimization, Vol. 11, No. 4, 2001, pp.
859-869. doi:10.1137/S1052623499354989
[15] T. G. Kolda, R. M. Lewis and V. Torczon, “Optimization
by Direct Search: New Perspectives on Some Classical
and Modern Methods,” SIAM Review, Vol. 45, No. 3,
2003, pp. 385-482. doi:10.1137/S003614450242889
[16] T. G. Kolda, R. M. Lewis and V. Torczon, “Stationary
Results for Generating Set Search for Linearly Con-
strained Optimization,” SIAM Journal on Optimization,
Vol. 17, No. 4, 2006, pp. 943-968.
doi:10.1137/S1052623403433638
[17] R. M. Lewis, A. Shepherd and V. Torczon, “Implement-
ing Generating Set Search Methods for Linearly Con-
strained Minimization,” SIAM Journal on Scientific Com-
puting, Vol. 29, No. 6, 2007, pp. 2507-2530.
doi:10.1137/050635432
[18] I. D. Coope and C. J. Price, “Frame Based Methods for
Unconstrained Optimization,” Journal of Optimization
Theory and Applications, Vol. 107, No. 2, 2000, pp. 261-
274. doi:10.1023/A:1026429319405
[19] I. D. Coope and C. J. Price, “A Direct Search Frame-
Based Conjugate Gradients Method,” Journal of Compu-
tational Mathematics, Vol. 22, No. 4, 2004, pp. 489-500.
[20] W. Y. Cheng, “A Two-Term PRP-Based Descent Method,”
Numerical Functional Analysis and Optimization, Vol. 28,
No. 11-12, 2007, pp. 1217-1230.
doi:10.1080/01630560701749524
[21] W. W. Hager and H. Zhang, “A New Conjugate Gradient