Circuits and Systems
Vol.07 No.08(2016), Article ID:67507,9 pages
10.4236/cs.2016.78152
CELLA: FPGA Based Candidate Execution with Low Latency Approach for Soft MIMO Detector
Erulappan Sakthivel1, Kasinathan Pounraj1, Veluchamy Malathi2, Muruganantham Arunraja1, Govindaraj Perumalvignnesh3
1Electrical and Electronics Engineering, SBM College of Engineering, Dindigul, India
2Electrical and Electronics Engineering, Anna University Regional Campus, Madurai, India
3Electrical and Electronics Engineering, The Silicon Harvest, Madurai, India

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 16 March 2016; accepted 5 April 2016; published 20 June 2016
ABSTRACT
This paper describes the design and Field Programmable Gate Array (FPGA) based 4 × 4 breadth heuristic Multiple-Input―Multiple-Output (MIMO) decoder using 16 and 64 Quadrature Amplitude Modulation (QAM) schemes. The intention of this work is to observe the performance of Candidate Execution with Low Latency Approach for soft MIMO detector in FPGA (CELLA). The Smart Ordering and Candidate Adding (SOCA), Parallel Candidate Adding (PCA) and Backward Candidate Adding (BCA) give better performance in terms of Bit Error Rate (BER) or chip level service. In order to attain both BER and FPGA level performance in a single system, CELLA is developed in this work. Simulation and experimental results demonstrate the effectiveness of the proposed work under the system 4 × 4 MIMO-OFDM employing 16 QAM and 64 QAM. The proposed experiment is implemented in Xilinx Virtex 5 C5VSX240T. The performance results, in terms of FPGA level 76% slice reduction, 58.76% throughput improvement, 75% power reduction and 87% latency reduction, are achieved. The BER performance is observed and compared with the conventional algorithms. Thus, the proposed work achieves better outcome than the conventional work.
Keywords:
Multiple-Input―Multiple-Output (MIMO), Field Programmable Gate Array, Parallel Candidate Adding

1. Introduction
In today’s data-rich world, MIMO has become an energetic element of wireless communication standard for high data rate communications. MIMO is a method for multiplying the capacity using multiple transmit and for receiving antennas to make use of multipath propagation. The method of incorporating turbo code in MIMO system is labeled as turbo coded MIMO system. Using the sphere decoder, a simple method is used to detect and decode linear space-time mapping with any channel code and it is called “soft” inputs and outputs [1] . To simplify the exponentially complex search problem in ML decoders for MIMO systems with greater modulation constellations, sphere decoders are accomplished by realizing near-ML performance with reasonable complexity. Moreover, the lattice decoders can be stretched to care soft decision outputs and, hence, be used in an iterative MIMO receiver. The lattice decoding algorithms have two kinds of application strategies. The first one is called Fincke―Pohst strategy and Schnorr―Euchner strategy. To avoid confusion, the lattice decoder using the Fincke―Pohst strategy is called a Sphere Decoder (SD), and the lattice decoder using the Schnorr―Euchner strategy is called SE. A List Sphere Decoding (LSD) algorithm can be used to effectively find the candidate list. The recognized list type of MIMO decoding algorithms is List Sphere Decoding (LSD) algorithm. The two major problems of the List Sphere Decoder (LSD) are variable complexity and the sequential nature of its tree search. To overcome these issues, a Fixed-complexity Sphere Decoder (FSD) is modified as List FSD (LFSD) [2] , which performs iterative detection and decodes in turbo Multiple Input Multiple Output (MIMO) systems. This method obtains a list of candidates for calculating likelihood information about the transmitted bits required by the outer decoder [2] . Because of lesser amount of information about expanded candidates, Soft-FSD (SFSD) can be used in turbo-MIMO systems to replace extrinsic soft-information to the outer decoder. It is used to provide the exact performance for the LSD with constant throughput and fixed complexity, by making the algorithm more suitable for hardware implementation [2] [3] . The negative aspects of the soft decoder are variable throughput, noise level and the channel conditions.
In [4] FPGA implementation of a new detection algorithm based on SD is introduced for MIMO systems. This paper algorithm overcomes the main drawback of the SD: its variable throughput, depending on the noise level and the channel environments. The performance results of Barbero et al. show that the algorithm is extremely parallelizable and can be completely pipelined. In [5] PCA scheme is used for the soft-output sphere decoder to identify the partial Maximum A Posteriori Estimation (MAP) estimation based on parent nodes in the place of child nodes. It provides low decoding latency and it is suitable for fully pipelined hardware implementation. In order to achieve optimal error rate performance with minimal power consumption, an adaptive switching detection algorithm is designed to incorporate multiple thresholds within the detector, which is implemented in XilinxVirtex-5 simulation hardware [6] .
Michael et al. have introduced a low-cost parallel programmable co-processor, which can achieve high throughput in ASIC/FPGA designs [7] . In [8] a novel MIMO detection algorithm is introduced which is also called Modified Fixed-Complexity Soft-Output (MFCSO) detection. This MFCSO used achieves better performance in terms of bandwidth and hardware implementation cost. The Maximum Likelihood Detector (MLD), QR decomposition with M-algorithm (QRM) and Fixed-complexity Sphere Decoding (FSD) [9] are used to calculate soft information of each coded bit. This approach can retrieve the coded bits and thus can recalculate the soft information with improved error performance under the system with 4 × 4 MIMO-OFDM employing 16 QAM and 64 QAM. Parallel bidirectional scheme [10] obtains a list of candidates to calculate likelihood information in parallel and each stage corresponds to one direction of the path selection process. Due to its parallel nature, it is well suited for hardware implementation, and it achieves better performance with lower complexity than a LFSD. For the data detection stage based on column-norm categorizing fully parallel GPU and multicore are used in [11] . These modules are developed to match the multicore architecture efficiently which has lesser computational time. It supports some of the configurations in the Long Term Evolution (LTE) standard [11] . The rest of this paper is organized as follows. Section 2 addresses the system model. Conventional detectors are discussed in Section 3. Proposed work and its module details are discussed in Section 4. The experimental results are presented in Section 5. Finally, the conclusion is presented in Section 6.
2. System Model
The system model specification is similar to that of Takuma et al. [9] . Here, in Low Density Parity Check (LDPC) coded MIMO system, Nt represents transmit antennas and Nr represents receive antennas (Nr ≥ Nt). These antennas are identically distributed. The binary information (input) is passed through LDPC encoder (by a rate γc) and an interleaver. The final results are mapped into symbols. These symbols are demultiplexed into Nt sub modules and passed through OFDM section. The vector consisting of the Nr receives symbols
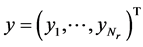 and is given by,
and is given by,
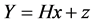 (1)
(1)
where 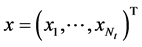 is the transmit vector with normalized transmit power
is the transmit vector with normalized transmit power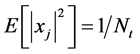 ;
;
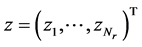 is the vector of independent and identically distributed; complex Additive White Gaussian Noise (AWGN) with variance of σ2 = N0, and H is the Nr ´ Nt Rayleigh fading channel matrix, where its element hij is the complex transfer function from transmitter j to receiver i with
is the vector of independent and identically distributed; complex Additive White Gaussian Noise (AWGN) with variance of σ2 = N0, and H is the Nr ´ Nt Rayleigh fading channel matrix, where its element hij is the complex transfer function from transmitter j to receiver i with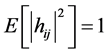 . The receiver section con-
. The receiver section con-
sists of MIMO detector, deinterleaver and LDPC decoder. The calculation of A Posteriori Probability (APP) for each of the coded bits b(j,k) is taken in the form of Log Likelihood Ratio (LLR). From [9] , the LLR equation is refined as per the proposed system.
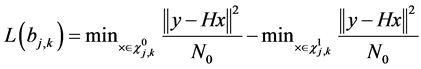 (2)
(2)
The list size upsets the complexity of the system, since the computational load increases linearly with the list size. To avoid this issue, the insertion of the list is removed from [9] and it is represented in Equation (2).
3. Conventional Detectors
The conventional algorithm for visited nodes and the list size are listed in Table 1 and Table 2. The maximum level of complexity is MLD, where visited nodes are 69,904 and the list size is 65,536 in 16 QAM.
The above values are reduced by introducing QRM concept. The visited node is 784 and the list size is 16 in 16 QAM whereas in the 64 QAM, the visited node is 5824 and the list size is 30. After that, LFSD, PCA and BCA combination of QRM-BCA and PCA-BCA visited node and list node are listed for both 16 QAM and 64 QAM. On comparing these concepts, the proposed methodology describes lesser consumption of visited nodes in the order of 34 and there is a decrease in the value of list size in the order of 16 in the 16 QAM. On the other hand, if we are considering 64 QAM case, visited nodes and list size do not give a drastic change like the above- described methodologies. This minimizes the size of Look Up Table (LUT). The decrease in the LUT simultaneously reduces the use of nodes and therefore, the slices are partially used in a considerable percentage.

Table 1. The number of visited nodes and list size.
Table 2. The number of visited nodes and list size with 16-QAM and 64-QAM.
4. Proposed Work
SOCA scheme is used to identify the partial MAP using parent nodes [12] . Conventional detectors are complex in nature, because it has maximum number of child nodes to identify the partial MAP. In SOCA, PCA [5] and BCA, the maximum number of child and parent nodes are available. In conventional architecture, the activities of child and parent nodes differ from under working node, but the overall architecture is the same as that of the previous work. In Figure 1, PCA, SOCA and CELLA architecture layouts are indicated. In order to reduce the complexity and for further performance in CELLA, a child node and single PE are represented to identify the partial MAP.
4.1. Candidate Execution with Low Latency Approach (CELLA)
The counterhypotheses of conventional SOCA, PCA and BCA algorithms are added in parallel with other candidates. From the hardware aspects, Look-Up Table (LUT) is introduced for counterhypotheses, and which is used to reduce the latency [5] . The overall resources in SOCA, PCA and BCA slightly differ from one another. Takuma et al. [9] report the visited node and the list size of conventional work, and they are indicated in Table 1 and Table 2. The proposed work is compared with the conventional FPGA family. The major problem of the conventional research (FSD [4] , SOCA [12] , and PCA [5] ) is the performance analysis, which is based on MATLAB Simulink environment model with Xilinx platform.
In order to convert the Simulink to Xilinx, conversion process utilizes more LUT and memory. Due to this complexity, the performance degradation occurs in the conventional architecture in FPGA level. To evade this issue, the conventional architecture is modeled using a VHDL implementation in Xilinx ISE Design Suite 12.1.
The pseudo-code of the CELLA scheme is given in Figure 2 (also refer pseudo-code of the PCA [5] in Figure 1 and pseudo-code of the SOCA [12] in Figure 2). The identification of the partial MAP node is performed in SOCA and PCA. The hardware complexity is slightly reduced in PCA than SOCA. For aggressive low complexity, the proposed concept is introduced. Here, the identification of the partial MAP node takes place within a single PE and MIN Search Unit (MSU). But, PCA and SOCA architectures have same number of extended child nodes with MSUs and parent node. In the proposed system, the identification of partial MAP node is performed by parent node without any additional child node (see Figure 2). This deals with the minimized consumption of the nodes with the above-described elements. It works in a conventional way but with the reduction in the consumption of nodes. This makes the best performance in the usage of nodes and when it is seen microscopically, the motto of the power reduction is achieved at the rate of 141 mw and 40 mw, which correspond to the 64 QAM and 16 QAM, respectively.
4.2. Hardware Architecture
Figure 2 shows the top-level architecture of the SOCA, PCA, and the proposed schemes in 4 × 4 16 QAM and 64 QAM systems. It is assumed that the Processing Elements (PEs) have been implemented to compute the required Euclidean Distance (ED) metrics. This experimental case study of the proposed system is carried out using Xilinx Virtex 5 XC5VSX240T. All 4 × 4 architectures are represented in a pipeline manner so that, it takes



Figure 1. Layout of conventional and proposed detector.
only 4 cycles to obtain the entire list for every transmitted vector after a single latency, while the detector receives a throughput of 400 Mbps at a clock frequency of 100 MHz.
The functional modules of MSU are comparator and decision logic. The MSU is used to identify the local MAP node and the architecture is made so that, each PE processes 4 nodes sequentially. In PCA, 3 MSUs are employed to deal with the counterhypotheses list, which contains (4 × 3) + (4 × 2) + 4 = 24 nodes. To handle it, 6 numbers of PEs are required, whereas in the proposed scheme, only one MSU and single PE are required to deal with the counterhypotheses list, which contains 4 × 1 + 4 × 1 + 4 = 12 nodes. As a result of hardware elimination (Removal of 4 PEs and MSU) in the proposed work, the performance improvements in terms of throughput give a range of 970 Mbps at 16 QAM and 830 Mbps at 64 QAM.

Figure 2. The proposed scheme in the form of algorithm.
The clock frequency obtained here is in the range of 150 MHz for two modulation architectures. They turn out with the power reduction in the range of 40 mw and 141 mw in 16 QAM and 64 QAM, respectively. The above- mentioned features are extended with the previously proposed metrics, and there is an improved standard in terms of reduction in latency, reduction in usage of slices, and improved data throughput. The most important term is the reduction in the usage of power that makes a standard among all the previous mentioned standards. When the throughput of CELLA is compared, the reduction in latency cycles also makes a greater contribution in the throughput for both 16 QAM and 64 QAM architectures. It is detailed in the FPGA level performance, and that is also independent in the amount of noise level.
5. Result and Discussion
The performance results are observed in simulation platform via MATLAB environment and FPGA platform via Xilinx ISE Design Suite 12.1. The Bit Error Rate (BER) results of SOCA, PCA, BCA, PCA + BCA, and CELLA are observed.
5.1. BER Performance
The BER performance has been obtained by computer simulation using 64-subcarrier OFDM per transmit antenna. Block Rayleigh fading is used for the channel model, where the ordering is required only once at the beginning of each received block. The rate of the LDPC code is chosen as ɣc =1/2, and the length of the code word is N = 3072 bits with maximum number of sum-product iteration T = 40, and Lmax = 8. First, Figure 3 compares the BER performance of the SOCA, BCA, PCA, PCA-BCA, and the CELLA using sibling nodes. It is observed from the case of CELLA work, even if the sibling nodes are selected, there is a performance improvement in the proposed work and it is better than other conventional works. The sibling nodes indicate the difference of throughput (Eb/No) of sibling nodes and the difference between the BER with the proposed and also the conventional algorithms.
5.2. FPGA Level Performance
In Table 3, the performance outcomes of the conventional, and the proposed works are compared. The various algorithms are analyzed. In optimized FSD-B algorithm [2] , 16 QAM is used to obtain 24,815 slices, 39,800 FFs and 31,759 LUT. The latency and throughput are 78 and 450 Mbps, respectively. Similarly, these results are obtained for algorithms such as K-Best SD [3] , PIPSD [13] and FSD 2 [4] , and which are implemented in Xilinx platform. The power values are not observed in these methods. Xiang et al. introduced PCA method [5] to attain better results compared to LFSD and SOCA works. The PCA results in 9471 slices, 22,814 FFs, 24,126 LUT, 174 DSP and 70 BRAM with latency cycles of 109 without power calculation. To overcome these problems and to reduce the area, a new method with various modulation levels (16 QAM and 64 QAM) is introduced in
 (a)
(a) (b)
(b)
Figure 3. BER performance using sibling node with the length of code word 3072 rate 1/2 LDPC code with 16-QAM, and 64-QAM in a 4 × 4 MIMO.
Table 3. Performance comparison of conventional and proposed work.
CELLA. They obtain 2215 slices, 4918 FFs, and 4982 LUT with latency of 14 cycles in 16 QAM. Similarly, these results are obtained in 64 QAM. The proposed method achieves the power value of 40 mw, 141 mw in 16 QAM and 64 QAM, respectively. This method is implemented in (FPGA platform) Xilinx Virtex5 XC5VSX240T. The experimental results of the proposed system are implemented in Xilinx Virtex5 XC5VSX240T platform. The performance analysis at FPGA level attains 76% slice reduction, 58.76% throughput improvement at 20 db, 75% power reduction and 87% latency reduction when compared to the conventional work. The
6. Conclusion
In this work, a candidate execution with low latency approach has been introduced for a turbo coded MIMO system. The proposed system identifies partial MAP nodes during online process and adds counterhypothesis in parallel within the parent candidate, which indicates the use of child nodes. This is not included here to minimize the ED distance metrics. The experimental results of the proposed system are implemented in Xilinx Virtex 5 XC5VSX240T platform. The performance analysis at FPGA level attains 76% slice reduction, 58.76% throughput improvement at 20 db, 75% power reduction and 87% latency reduction when compared to the conventional work. The BER performance is also computed for the proposed and conventional algorithms. It minimizes the noise level and improves the performance boost at 20 db/s. Thus, it proves the execution of the nodes in the confined region compared to other algorithms. Thus, CELLA achieves the best performance than the conventional work.
Cite this paper
Erulappan Sakthivel,Kasinathan Pounraj,Veluchamy Malathi,Muruganantham Arunraja,Govindaraj Perumalvignnesh, (2016) CELLA: FPGA Based Candidate Execution with Low Latency Approach for Soft MIMO Detector. Circuits and Systems,07,1760-1768. doi: 10.4236/cs.2016.78152
References
- 1. Barbero, L.G. and Thompson, J.S. (2006) FPGA Design Considerations in the Implementation of a Fixed-Throughput Sphere Decoder for MIMO Systems. 2006 International Conference on Field Programmable Logic and Applications, Madrid, 28-30 August 2006, 1-6.
http://dx.doi.org/10.1109/fpl.2006.311247 - 2. Barbero, L.G. and Thompson, J.S. (2008) Extending a Fixed-Complexity Sphere Decoder to Obtain Likelihood Information for Turbo-MIMO Systems. IEEE Transactions on Vehicular Technology, 57, 2804-2814.
http://dx.doi.org/10.1109/TVT.2007.914064 - 3. Mondal, S., Eltawil, A., Shen, C.A. and Salama, K.N. (2010) Design and Implementation of a Sort-Free K-Best Sphere Decoder. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 18, 1497-1501.
http://dx.doi.org/10.1109/TVLSI.2009.2025168 - 4. Barbero, L.G. and Thompson, J.S. (2006) Rapid Prototyping of a Fixed-Throughput Sphere Decoder for MIMO Systems. IEEE International Conference on Communications, 7, 3082-3087.
http://dx.doi.org/10.1109/ICC.2006.255278 - 5. Wu, X. and Thompson, J.S. (2011) A Fixed-Complexity Soft-MIMO Detector via Parallel Candidate Adding Scheme and Its FPGA Implementation. IEEE Communications Letters, 15, 241-243.
http://dx.doi.org/10.1109/LCOMM.2011.010311.101626 - 6. Tadza, N., Laurenson, D. and Thompson, J.S. (2014) Adaptive Switching Detection Algorithm for Iterative-MIMO Systems to Enable Power Savings. Radio Science, 49, 1065-1079.
http://dx.doi.org/10.1002/2013RS005323 - 7. Wu, M., Sun, Y., Gupta, S. and Cavallaro, J.R. (2011) Implementation of a High Throughput Soft MIMO Detector on GPU. Journal of Signal Processing Systems, 64, 123-136.
http://dx.doi.org/10.1007/s11265-010-0523-4 - 8. Wu, D., Eilert, J., Asghar, R. and Liu, D. (2010) VLSI Implementation of a Fixed-Complexity Soft-Output MIMO Detector for High-Speed Wireless. EURASIP Journal on Wireless Communications and Networking, 58, Article ID: 893184.
http://dx.doi.org/10.1155/2010/893184 - 9. Tsubaki, T. and Ochiai, H. (2013) A New Candidate Adding Algorithm for Coded MIMO Systems with Fixed-Com- plexity Detection. 2013 IEEE International Conference on IEEE Communications (ICC), Budapest, 9-13 June 2013, 4525-4529.
http://dx.doi.org/10.1109/icc.2013.6655281 - 10. Zhen, X., Zhou, X., Huai, L. and Sobelman, G.E. (2013) A Novel Fixed-Complexity Soft-Output MIMO Detector Using Parallel Bidirectional Scheme. 2013 IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC), Kunming, 5-8 August 2013, 1-4.
http://dx.doi.org/10.1109/icspcc.2013.6664024 - 11. Roger, S., Ramiro, C., Gonzalez, A., Almenar, V. and Vidal, A.M. (2012) Fully Parallel GPU Implementation of a Fixed-Complexity Soft-Output MIMO Detector. IEEE Transactions on Vehicular Technology, 61, 3796-3800.
- 12. Milliner, D.L., Zimmermann, E., Barry, J.R. and Fettweis, G. (2009) A Fixed-Complexity Smart Candidate Adding Algorithm for Soft-Output MIMO Detection. IEEE Journal of Selected Topics in Signal Processing, 3, 1016-1025.
http://dx.doi.org/10.1109/JSTSP.2009.2035800 - 13. Fan, A., Qin, X. and Dai, X. (2014) A Partial Inter-Layer Parallel Sphere Decoder for Multiple-Input Multiple-Output Systems. 2014 6th International Conference on Wireless Communications and Signal Processing (WCSP), Hefei, 23- 25 October 2014, 1-6.