Journal of Computer and Communications
Vol.2 No.1(2014), Article ID:41684,6 pages DOI:10.4236/jcc.2014.21005
Learning Dynamics of the Complex-Valued Neural Network in the Neighborhood of Singular Points
![]()
National Institute of Advanced Industrial Science and Technology (AIST), Tsukuba, Japan.
Email: tohru-nitta@aist.go.jp
Received December 4th, 2013; revised December 28th, 2013; accepted January 4th, 2014
ABSTRACT
In this paper, the singularity and its effect on learning dynamics in the complex-valued neural network are elucidated. It has learned that the linear combination structure in the updating rule of the complex-valued neural network increases the speed of moving away from the singular points, and the complex-valued neural network cannot be easily influenced by the singular points, whereas the learning of the usual real-valued neural network can be attracted in the neighborhood of singular points, which causes a standstill in learning. Simulation results on the learning dynamics of the three-layered real-valued and complex-valued neural networks in the neighborhood of singularities support the analytical results.
Keywords:Complex-Valued Neural Network; Complex Number; Learning; Singular Point
1. Introduction
Complex-valued neural networks have been applied in various fields dealing with complex numbers or twodimensional data such as signal processing and image processing [1,2]. The complex-valued neural network can represent more information than the real-valued neural network because the inputs, the weights, the threshold values, and the outputs are all complex numbers, and the complex-valued neural network has some inherent properties such as the ability to transform geometric figures [3-5] and the orthogonal decision boundary [6,7].
In the applications of the multi-layered type real-valued neural networks, the error back-propagation learning algorithm (called here, Real-BP [8]) has often been used. Naturally, the complex-valued version of the Real-BP (called here, Complex-BP) can be considered, and was actually proposed by several researchers independently in the early 1990’s [3-5,9-11]. This algorithm enables the network to learn complex-valued patterns naturally.
On one hand, the researches on the singularity of the learning machines with a hierarchical structure have progressed in the past several years [12-15]. It has turned out that the singularity has a negative effect on learning dynamics in the learning machines such as real-valued neural networks and gaussian mixture models. Here, a singular point is a point on which the derivatives of an error function are all zero, that is, it is a critical point and can be a local minimum, a local maximum or a saddle point.
In this paper, the singularity and its effect on learning dynamics in the complex-valued neural network are elucidated. As a result, we find that the linear combination structure in the updating rule of the complex-valued neural network increases the speed of moving away from the singular points; the complex-valued neural network cannot be easily influenced by the singular points, whereas the learning of the usual real-valued neural network can be attracted in the neighborhood of singular points, which causes a standstill in learning. Simulation results on the learning dynamics of the three-layered real-valued and complex-valued neural networks in the neighborhood of singularities support the analytical results. It should be noted here that it has been reported that the learning speed of the Complex-BP is two or three times faster than that of the Real-BP on average via computer simulations [5,16]. This is due to the learning structure of the complex-valued neural networks described above.
2. Problem on the Singularity
Recently, it has turned out that the singularity has a negative effect on learning dynamics in the real-valued neural networks [12,13,15]. That is, the hierarchical structure or a symmetric property on exchange of weights of the the real-valued neural networks have singular points. For example, if a weight v between a hidden neuron and an output neuron is eaual to zero, then no value of the weight vector w between the hidden neuron and the input neurons affects the output value of the real-valued neural network. Then, the weight v is called an unidentifiable parameter, which is a kind of singular point. It has been proved that singular points affect the learning dynamics of learning models, and that they can cause a standstill in learning.
3. The Complex-Valued Neural Network
This section describes the complex-valued neural network used in the analysis. First, we will consider the following complex-valued neuron. The input signals, weights, thresholds and output signals are all complex numbers. The net input Un to a complex-valued neuron n is defined as: 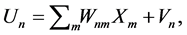 where Wmm is the (complexvalued) weight connecting the complex-valued neurons n and m, Xm is the (complex-valued) input signal from the complex-valued neuron m, and Vn is the (complex-valued) threshold value of the complex-valued neuron n. To obtain the (complex-valued) output signal, convert the net input Un into its real and imaginary parts as follows:
where Wmm is the (complexvalued) weight connecting the complex-valued neurons n and m, Xm is the (complex-valued) input signal from the complex-valued neuron m, and Vn is the (complex-valued) threshold value of the complex-valued neuron n. To obtain the (complex-valued) output signal, convert the net input Un into its real and imaginary parts as follows: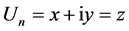 , where i denotes
, where i denotes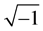 . The (complexvalued) output signal is defined to be
. The (complexvalued) output signal is defined to be
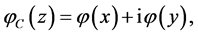 (1)
(1)
where
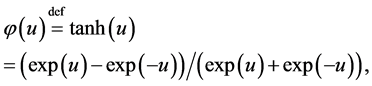
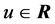 (R denotes the set of real numbers) and is called hyperbolic tangent. Note that
(R denotes the set of real numbers) and is called hyperbolic tangent. Note that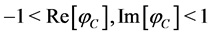 . Note also that
. Note also that 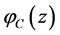 is not holomorphic as a complex function because the Cauchy-Riemann equations do not hold:
is not holomorphic as a complex function because the Cauchy-Riemann equations do not hold:
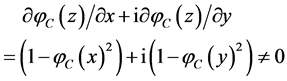
where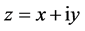 .
.
A complex-valued neural network consists of such complex-valued neurons described above. The network used in the analysis will have 3 layers: L-H-1 network. The activation function 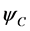 of the output neuron is linear, that is,
of the output neuron is linear, that is, 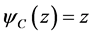 for any
for any 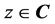 where
where 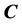 denotes the set of complex numbers. For any input pattern
denotes the set of complex numbers. For any input pattern 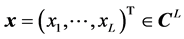 to the complex-valued neural network where
to the complex-valued neural network where 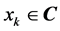 is the input signal to the input neuron
is the input signal to the input neuron 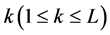 and
and 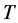 denotes transposition, the output value of the output neuron is defined to be
denotes transposition, the output value of the output neuron is defined to be
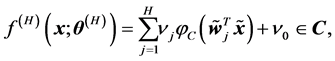 (2)
(2)
where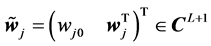 ,
, 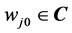 is the threshold of the hidden neuron
is the threshold of the hidden neuron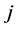 ,
, 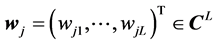
is the weight vector of the hidden neuron 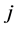 (
(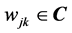 is the weight between the input neuron
is the weight between the input neuron 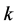 and the hidden neuron
and the hidden neuron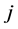 )
)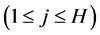 ,
, 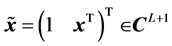 ,
, 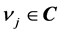 is the weight between the hidden neuron
is the weight between the hidden neuron 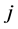 and the output neuron
and the output neuron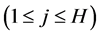 ,
, 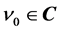 is the threshold of the output neuron, and
is the threshold of the output neuron, and 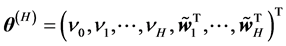 which summarizes all the parameters in one large vector.
which summarizes all the parameters in one large vector.
Given 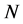 complex-valued training data
complex-valued training data
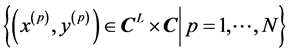 , we use a complexvalued neural network to realize the relation expressed by the data. The objective of the training is to find the parameters that minimize the error function defined by
, we use a complexvalued neural network to realize the relation expressed by the data. The objective of the training is to find the parameters that minimize the error function defined by
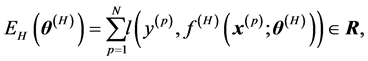 (3)
(3)
where 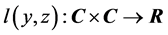 is a loss function such that
is a loss function such that 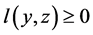 and the equality holds if and only if
and the equality holds if and only if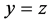 . Note that
. Note that 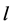 is not holomorphic as a complex function because it takes a real value. To the author’s knowledge, all of the multi-layered complex-valued neural networks proposed so far (for example [3-5,9-11]) employ the mean square error
is not holomorphic as a complex function because it takes a real value. To the author’s knowledge, all of the multi-layered complex-valued neural networks proposed so far (for example [3-5,9-11]) employ the mean square error 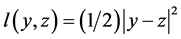 which takes a real value.
which takes a real value.
4. Analytical Dynamics
This section reveals the behavior of the three-layered complex-valued neural network in the neighborhood of singular points, compared with that of the three-layered real-valued neural network via theoretical analysis.
Consider a 1-1-1 complex-valued neural network described in Section 3 for the sake of simplicity. For any input signal 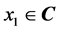 to the complex-valued neural network, the output value of the output neuron is defined to be
to the complex-valued neural network, the output value of the output neuron is defined to be
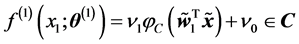 (4)
(4)
where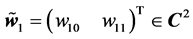 ,
, 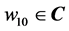 is the threshold of the hidden neuron,
is the threshold of the hidden neuron,  is the weight between the input neuron and the hidden neuron,
is the weight between the input neuron and the hidden neuron, 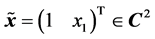 ,
, 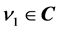 is the weight between the hidden neuron and the output neuron,
is the weight between the hidden neuron and the output neuron, 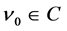 is the threshold of the output neuron, and
is the threshold of the output neuron, and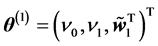 . The number of learnable parameters (weights and thresholds) is 8 where a complex-valued parameter is counted as two because it consists of a real part and an imaginary part. The loss function is defined as
. The number of learnable parameters (weights and thresholds) is 8 where a complex-valued parameter is counted as two because it consists of a real part and an imaginary part. The loss function is defined as
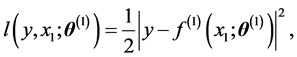 (5)
(5)
where 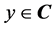 is the training signal for the output neuron.
is the training signal for the output neuron.
In the case of the standard gradient learning method, the average learning dynamics is given as follows:
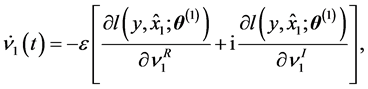 (6)
(6)
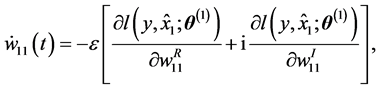 (7)
(7)
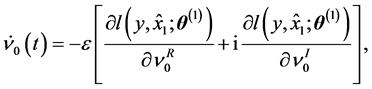 (8)
(8)
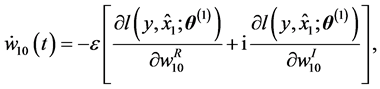 (9)
(9)
where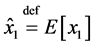 ,
, 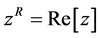 and
and 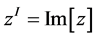 for a learnable parameter
for a learnable parameter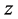 .
.
Then, we investigate the behavior of the weight 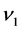 between the hidden neuron and the output neuron in the neighborhood of the singularity
between the hidden neuron and the output neuron in the neighborhood of the singularity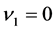 . Letting
. Letting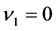 , from Equation (6), we can easily obtain
, from Equation (6), we can easily obtain
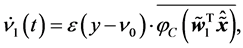 (10)
(10)
where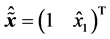 .
.
Next, consider a 2-1-2 real-valued neural network. For any input signal 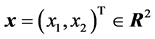 to the real-valued neural network, the output value of the real-valued neural network is defined to be
to the real-valued neural network, the output value of the real-valued neural network is defined to be
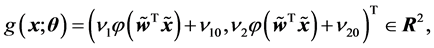 (11)
(11)
where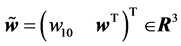 ,
, 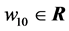 is the threshold of the hidden neuron,
is the threshold of the hidden neuron, 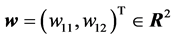 is the weight vector between the input neurons and the hidden neuron (
is the weight vector between the input neurons and the hidden neuron (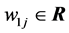 is the weight between the input neuron
is the weight between the input neuron 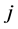 and the hidden neuron
and the hidden neuron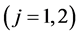 ),
), 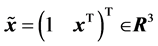 ,
,
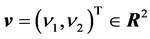 is the weight vector between the hidden neuron and the output neurons (
is the weight vector between the hidden neuron and the output neurons (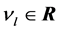 is the weight between the hidden neuron and the output neuron
is the weight between the hidden neuron and the output neuron 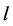
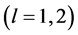 ),
), 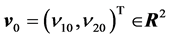 is the threshold vector of the output neurons (
is the threshold vector of the output neurons (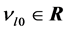 is the threshold of the output neuron
is the threshold of the output neuron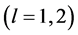
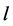 ),
), 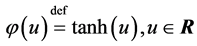 , and
, and
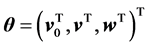 . The number of learnable parameters (weights and thresholds) is 7, which is almost equal to that of the complex-valued neural network described above. Thus, the comparison of the learning dynamics using those neural networks is fair. The loss function is defined as
. The number of learnable parameters (weights and thresholds) is 7, which is almost equal to that of the complex-valued neural network described above. Thus, the comparison of the learning dynamics using those neural networks is fair. The loss function is defined as
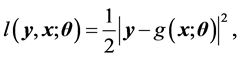 (12)
(12)
where 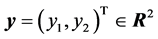 is the training signal for the output neurons.
is the training signal for the output neurons.
The average learning dynamics of the real-valued neural network using the standard gradient learning method is given as follows:
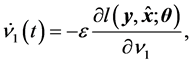 (13)
(13)
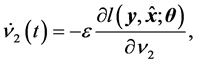 (14)
(14)
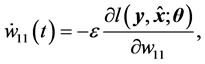 (15)
(15)
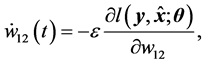 (16)
(16)
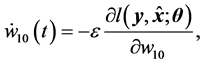 (17)
(17)
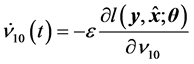 (18)
(18)
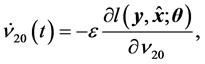 (19)
(19)
where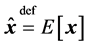 . Letting
. Letting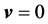 , from Equations (13)
, from Equations (13)
and (14), we can easily obtain
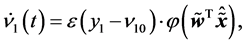 (20)
(20)
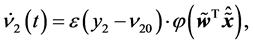 (21)
(21)
where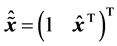 . This is the average dynamics of the weights
. This is the average dynamics of the weights 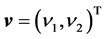 between the hidden neuron and the output neurons in the neighborhood of the singularity
between the hidden neuron and the output neurons in the neighborhood of the singularity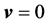 .
.
We compare below the average dynamics of the complex-valued neural network with that of the real-valued neural network in the neighborhood of singularity. Equation (10) can be rewritten as
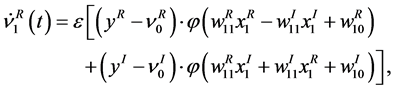 (22)
(22)
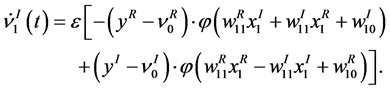 (23)
(23)
As shown in Equations (22) and (23),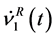 and
and 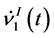 consist of two linear combinations of
consist of two linear combinations of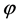 , respectively. The following are its explanatory equations.
, respectively. The following are its explanatory equations.
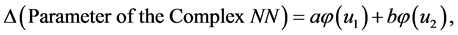 (24)
(24)
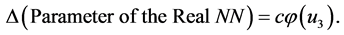 (25)
(25)
For example, if 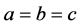 and
and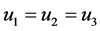 , then
, then 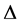 (Parameter of the Complex NN) =
(Parameter of the Complex NN) = 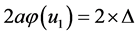 (Parameter of the Real NN) holds. And also,
(Parameter of the Real NN) holds. And also, 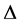 (Parameter of the Complex NN) cannot be equal to zero easily because
(Parameter of the Complex NN) cannot be equal to zero easily because 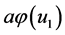 is not necessarily equal to zero even if one term on
is not necessarily equal to zero even if one term on 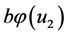 is almost equal to zero. This structure causes a high possibility of
is almost equal to zero. This structure causes a high possibility of 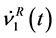 and
and 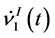 of taking larger values, compared with
of taking larger values, compared with 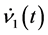 and
and 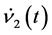 (Equations (20) and (21)). Thus, we can assume that the speed of the complex-valued neural network of moving away from the singularity is faster than that of the realvalued neural network.
(Equations (20) and (21)). Thus, we can assume that the speed of the complex-valued neural network of moving away from the singularity is faster than that of the realvalued neural network.
5. Simulations
We present below the simulation results on the learning dynamics of the three-layered complex-valued neural networks using the standard gradient learning method in the neighborhood of singularities, and compare them with those of the three-layered real-valued neural networks using the standard gradient learning method.
In the experiments, the three sets of (complex-valued) learning patterns shown in Table 1 were used, and the learning constant 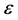 was 0.5. We chose the three-layered 1-1-1 complex-valued neural network where
was 0.5. We chose the three-layered 1-1-1 complex-valued neural network where 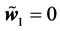 and
and 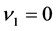 were singular points, and the three-layered 2-1-2 real-valued neural network where
were singular points, and the three-layered 2-1-2 real-valued neural network where 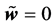 and
and 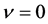 were singular points described in Section 4. The comparison using those neural networks is fair because the numbers of the parameters (weights and thresholds) are almost the same: the number of parameters for the 1-1-1 complexvalued network is 8, and that for the 2-1-2 real-valued neural network 7 where a complex-valued parameter
were singular points described in Section 4. The comparison using those neural networks is fair because the numbers of the parameters (weights and thresholds) are almost the same: the number of parameters for the 1-1-1 complexvalued network is 8, and that for the 2-1-2 real-valued neural network 7 where a complex-valued parameter 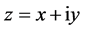 is counted as two because it consists of a real part
is counted as two because it consists of a real part 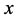 and an imaginary part
and an imaginary part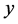 . In the real-valued neural network, the real component of a complex number was input into the first input neuron, and the imaginary
. In the real-valued neural network, the real component of a complex number was input into the first input neuron, and the imaginary
 (a) Learning pattern 1
(a) Learning pattern 1  (b) Learning pattern 2
(b) Learning pattern 2
 (c) Learning pattern 3
(c) Learning pattern 3
Table 1 . Learning patterns.
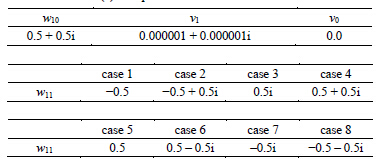
component was input into the second input neuron; the output from the first output neuron was interpreted to be the real component of a complex number, and the output from the second output neuron was interpreted to be the imaginary component. The initial values of the weights and the thresholds were set as shown in Table2 Note that the initial values of the weights between the hidden layer and the output layer were set in the neighborhood of the singular points: 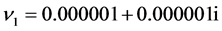 in the complex-valued neural network, and
in the complex-valued neural network, and 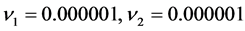 in the real-valued neural network. The eight initial values (eight cases) were used for the weights
in the real-valued neural network. The eight initial values (eight cases) were used for the weights 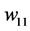 or
or 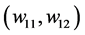 between the input layer and the hidden layer. We judged that learning finished, when the training error was equal to
between the input layer and the hidden layer. We judged that learning finished, when the training error was equal to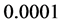 , that is,
, that is, 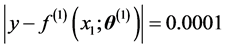 in the case of the complex-valued neural network, and
in the case of the complex-valued neural network, and 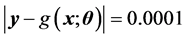 in the case of the real-valued neural network.
in the case of the real-valued neural network.
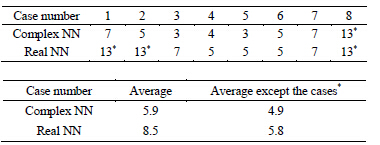
We investigated the learning speed (i.e., learning cycles needed to converge) for each of the 3 learning patterns in the experiments described above. The results of the experiments are shown in Table3 We can find from these experiments that the average learning speed of the complex-valued neural network is approximately 1.4 times faster than that of the real-valued neural network. The superscript * of a number means that the weights between the hidden layer and the output layer stayed in the neighborhood of the singular point 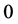 or
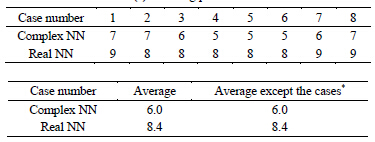
or 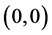 from the beginning to the end of leaning. Table 4 shows the Euclidean distances between the weights (between the hidden layer and the output layer) and the singular point
from the beginning to the end of leaning. Table 4 shows the Euclidean distances between the weights (between the hidden layer and the output layer) and the singular point 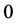 or
or 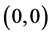 after the first learning cycle. In every case, the weights of the complex-valued neural network moved in the distance from the singular point
after the first learning cycle. In every case, the weights of the complex-valued neural network moved in the distance from the singular point  compared with those of the real-valued neural network. We believe that this phenomenon originates in the linear combinations of
compared with those of the real-valued neural network. We believe that this phenomenon originates in the linear combinations of  in Equations (22) and (23) shown in Section 4.
in Equations (22) and (23) shown in Section 4.
In the experiments on the learning patterns 1 and 2, the learning speeds of the cases * were slow uniformly. All the average learning speeds except the cases * were faster than the average learning speed. In the cases *, the
 (a) Complex-valued neural network
(a) Complex-valued neural network 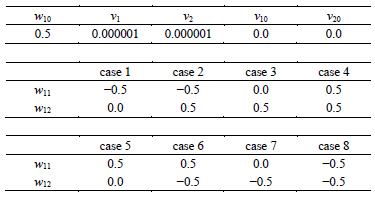 (b) Real-valued neural network
(b) Real-valued neural network
Table 2 . Initial values of the weights and the thresholds.
 (a) Learning pattern 1
(a) Learning pattern 1 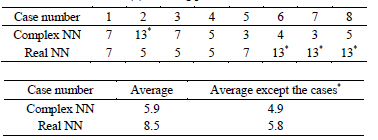 (b) Learning pattern 2
(b) Learning pattern 2
 (c) Learning pattern 3
(c) Learning pattern 3
Table 3. Learning speed (the number of learning cycles needed to converge). Case number means the initial values of the weights between the input layer and the hidden layer (See Table 2). The superscript * of a number means that the weights between the hidden layer and the output layer stayed in the neighborhood of the singlar point 0 or (0, 0) from the beginning to the end of leaning.
 (a) Learning pattern 1
(a) Learning pattern 1 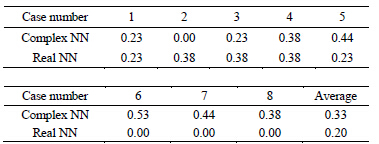 (b) Learning pattern 2
(b) Learning pattern 2
 (b) Learning pattern 2
(b) Learning pattern 2
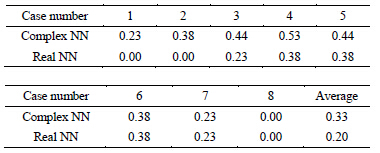
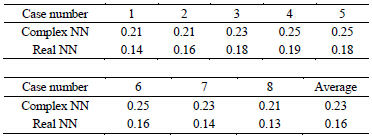
Table 4. The Euclidean distances between the weights (between the hidden layer and the output layer) and the singular point 0 or (0, 0) after the first learning cycle: 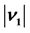 for the complex-valued network, and
for the complex-valued network, and 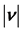 for the real-valued neural network. Case number means the initial values of the weights between the input layer and the hidden layer (See Table 2).
for the real-valued neural network. Case number means the initial values of the weights between the input layer and the hidden layer (See Table 2).
weights between the hidden layer and the output layer could not move away from the singular point, but, as a result, the learning speed became slow. And also, the number of cases * of the complex-valued neural network was 1, and that of the real-valued neural network 3, which suggested that the complex-valued neural network was not influenced by singular points compared with the real-valued neural network.
In the experiment on the learning pattern 3, the average learning speed of the complex-valued neural network was 1.4 times faster than that of the real-valued neural network, although there was no cases * in both of the neural networks. Figure 1 shows the weights between the hidden layer and the output layer after the first learning cycle and those after the learning finished for the learning pattern 3. Judging from Figure 1 and Table 4, the speed of the complex-valued neural network of moving away from the singularity is faster than that of the real-valued neural network, and it causes a difference of the learning speed.

Figure 1. The behavior of the weights between the hidden layer and the output layer. Their initial values were set in the neighborhood of the singular point (the origin). The eight initial values (eight cases) were used for the weights between the input layer and the hidden layer (see Table 2). The distance of the weight of the complex-valued neural network from the singularity after the first learning cycle was larger than that of the real-valued neural network.
6. Conclusions
We compared theoretically and experimentally the influence of the singular points on the learning dynamics in the complex-valued neural network with that in the realvalued neural network. As a result, we found that the linear combination structure in the updating rule of the complex-valued neural network increased the speed of moving away from the singular points; the complex-valued neural network could not be easily influenced by the singular points. This is considered to be a result which supports the fast convergence of the Complex-BP algorithm.
It might be premature to conclude the statements described above are true because this paper deals with only very simple cases such as the network structures and the learning patterns. In the future, we will investigate more complicated cases.
Acknowledgements
The author extends special thanks to the anonymous reviewers for valuable comments.
REFERENCES
- A. Hirose, Ed., “Complex-Valued Neural Networks,” World Scientific Publishing, Singapore, 2003.
- T. Nitta, Ed., “Complex-Valued Neural Networks: Utilizing High-Dimensional Parameters,” Information Science Reference, Pennsylvania, 2009. http://dx.doi.org/10.4018/978-1-60566-214-5
- T. Nitta and T. Furuya, “A Complex Back-Propagation Learning,” Transactions of Information Proceedings of the Society of Japan, Vol. 32, No. 10, 1991, pp. 1319- 1329.
- T. Nitta, “A Complex Numbered Version of the BackPropagation Algorithm,” Proceedings of the World Congress on Neural Networks, Portland, Vol. 3, 1993, pp. 576-579.
- T. Nitta, “An Extension of the Back-Propagation Algorithm to Complex Numbers,” Neural Networks, Vol. 10, No. 8, 1997, pp. 1392-1415. http://dx.doi.org/10.1016/S0893-6080(97)00036-1
- T. Nitta, “Orthogonality of Decision Boundaries in Complex-Valued Neural Networks,” Neural Computation, Vol. 16, No. 1, 2004, pp. 73-97. http://dx.doi.org/10.1162/08997660460734001
- T. Nitta, “Complex-Valued Neural Network and Complex-Valued Back-Propagation Learning Algorithm,” In: P. W. Hawkes, Ed., Advances in Imaging and Electron Physics, Elsevier, Amsterdam, Vol. 152, 2008, pp. 153- 221.
- D. E. Rumelhart, et al., “Parallel Distributed Processing,” Vol. 1, MIT Press, 1986.
- N. Benvenuto and F. Piazza, “On the Complex Backpropagation Algorithm,” IEEE Transactions on Signal Processing, Vol. 40, No. 4, 1992, pp. 967-969. http://dx.doi.org/10.1109/78.127967
- G. M. Georgiou and C. Koutsougeras, “Complex Domain Backpropagation,” IEEE Transactions on Circuits and Systems—II: Analog and Digital Signal Processing, Vol. 39, No. 5, 1992, pp. 330-334.
- M. S. Kim and C. C. Guest, “Modification of Backpropagation Networks for Complex-Valued Signal Processing in Frequency Domain,” Proceedings of the International Joint Conference on Neural Networks, Vol. 3, 1990, pp. 27-31.
- S. Amari, H. Park and T. Ozekii, “Singularities Affect Dynamics of Learning in Neuromanifolds,” Neural Computation, Vol. 18, No. 5, 2006, pp. 1007-1065. http://dx.doi.org/10.1162/neco.2006.18.5.1007
- F. Cousseau, T. Ozeki and S. Amari, “Dynamics of Learning in Multilayer Perceptrons near Singularities,” IEEE Transactions on Neural Networks, Vol. 19, No. 8, 2008, pp. 1313-1328. http://dx.doi.org/10.1109/TNN.2008.2000391
- T. Nitta, “Local Minima in Hierarchical Structures of Complex-Valued Neural Networks,” Neural Networks, Vol. 43, 2013, pp. 1-7. http://dx.doi.org/10.1016/j.neunet.2013.02.002
- H. Wei, J. Zhang, F. Cousseau, T. Ozeki and S. Amari, “Dynamics of Learning near Singularities in Layered Networks,” Neural Computation, Vol. 20, 2008, pp. 813-843. http://dx.doi.org/10.1162/neco.2007.12-06-414
- F. M. De Azevedo, S. S. Travessa and F. I. M. Argoud, “The Investigation of Complex Neural Network on Epileptiform Pattern Classification,” Proceedings of the 3rd European Medical and Biological Engineering Conference (EMBEC’05), 2005, pp. 2800-2804.