 Journal of Software Engineering and Applications, 2013, 6, 623-629 Published Online December 2013 (http://www.scirp.org/journal/jsea) http://dx.doi.org/10.4236/jsea.2013.612074 Open Access JSEA 623 A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services Chengwen Zhang1, Jiali Bian1, Bo Cheng2, Lingfei Li3 1Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia, Beijing University of Posts & Telecommuni- cations, Beijing, China; 2State Key Laboratory of Networking and Switching Technology, Beijing University of Posts & Telecom- munications, Beijing, China; 3Key Laboratory of Trustworthy Distributed Computing and Service (BUPT) of Ministry of Education, Beijing University of Posts & Telecommunications, Beijing, China. Email: paperbupt@126.com Received October 26th, 2013; revised November 20th, 2013; accepted November 27th, 2013 Copyright © 2013 Chengwen Zhang et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. In accor- dance of the Creative Commons Attribution License all Copyrights © 2013 are reserved for SCIRP and the owner of the intellectual property Chengwen Zhang et al. All Copyright © 2013 are guarded by law and by SCIRP as a guardian. ABSTRACT A personalized recommendation for cloud services, which is based on usage history and the cooperative relationship of cloud services, is presented. According to service groups, a service group could be defined as several services that were used together by one user at a time, and cooperative relationship between each two services can be calculated. In the process of recommendation, the services which are highly related to the service that the user has selected would be ob- tained firstly, the result should then take the QoS (Quality of Service) similarity between service’s QoS an d user’s pref- erence into account, so the final result combining the cooperative relationship and similarity will meet the functional needs of users and also meet the user’s personalized non-functional requirements. The simulation p roves that the algo- rithm works effectively. Keywords: Personalized Recommendation; Cloud Service; Quality of Service; Similarity; Co operative Relationship 1. Introduction Recommendation system is an in telligent agent system to solve the information overload problem on the Internet, which recommends choices that meet users’ needs or interests from a lot of information on the Internet to the users automatically. Personalized recommendation sys- tem is put forward as an indepe ndent concept in the 20th century until 1990, the first presented recommendation system is based on collaborative filtering recommenda- tion [1], including content-based similarity [2] and user- based similarity [3] recommended methods. And in re- cent years label concept [4] has been presented to im- prove for user’s single evaluation and the defects on the description of users and objects. Recommendation algo- rithm based on diffusion [5,6] and making use of graph theory bipartite graph [7-10] has also been presen ted, the physical diffusion theory is also used in the recommend- dation system in order to improve accuracy and reduce complexity. With the process of cloud computing in resent years, people begin to take their focus on the development of cloud service selection and recommendation [11-16]. Cloud computing environments utilize the SOA archi- tecture, including three aspects, they are service provid- ers, cloud providers and service users. Service providers no longer provide runtime environment for the release of the service, but utilize the cloud computing environment to run their specific services. Based on certain strategies, service providers select the appropriate cloud provider from the numerous cloud providers to run the specific services. And service users in the cloud computing envi- ronment select services which can meet their needs. The advantage of this architecture is that service providers and cloud providers run separately and have distinction permission, making logic service and the service envi- ronment separated, as well as bring about improving sca- lability and flexib ility. Cloud computing environment offers a wide variety of services that can be divided into different levels, from higher level to the lower level, they are Software applica-  A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services 624 tion level services, platforms or environmental level ser- vices and infrastructure level services. Actually, the users usually choose a number of services spontaneously to form a combination to meet their own needs instead of using fixed combinations or a single service that cannot meet the needs of users. For example, a user wants to edit text online, in addition to using text editing functions (This feature can be seen as a software application level functions), it also needs to be uploaded to the Internet and can be downloaded in different places, it can be seen as a memory function in basic level of service. Cloud ser- vices are complementary to each other in functional as- pects to achieve different goals. These services may in- clude a variety of service units, such as hardware, soft- ware, platform, storage, computing, data and other ser- vices. According to different requirements and rules, services are combined to realize the complex functions. According to the circumstances described above, a recommendation algorithm which is based on usage his- tory and the combined relationship of cloud services is presented. Firstly, system will extract the users’ usage of the group from services, then according to the group, calculate the cooperative relationship among services. While recommending, according to the service that user has chosen, system selects services which are highly re- lated to the service that the user has chosen, and gives final result which combines the cooperative relationship and similarity between QoS and user’s interests. The remaining chapters are organized as follows: Sec- tion 2 describes some related works; Section 3 discusses in detail including model design and algorithm steps de- sign; Section 4 presents the simulation work and results; Section 5 concludes the work and notes further research content. 2. Related Works The most mature algorithm is the collaborative filtering recommendation algorithm [1], which includes user-bas- ed and content-based method. [2,3] discussed the two collaborative filtering algorithms in detail. With the de- velopment of the research on recommendation system, recommendation algorithm is no longer limited to col- laborative filtering methods, but also make use of the network topology, this type of algorithms treats users and the projects as nodes, [5,6] discussed a network-based diffusion recommendation algorithm, according to the projects selected by user, it takes advantage of diffusion theory to find users wh o has si milar interests to the targ et user and makes recommendation. [8,9] presented an algorithm by making use of two sub-networks (also known as two parts diagram), ac- cording to the user’s choice of products and creating the relationships through a diffusion algorithm, algorithm finds out users’ potential demand or interest and makes recommendation. Algorithm presented in [9] weights edges in the network in order to improve the precision in recommending. [7] presented a recommendation and clustering algo- rithm that works by creating a network topology based services relationship. Services are divided into two parts: services with large and small granularity, called SOS and S. SOS is usually composed by a variety of services S and some programming supplemented, the relationships of composition can be shown by a SOS-S network. Ac- cording to this netwo rk structure, the diagrams that show the similarity relationship between large-grained services and the relationship between small-grained services can be calculated. Recommendation makes use of the com- bination relationship of small-grained services, and rec- ommends the services which are closely related to ac- cording to the selected service. 3. Recommendation Models and Methods Users and services are treated as nodes in this recom- mendation system, according to users’ usage record, ser- vices will be combined to form a service gro up. Based on the group’s composition and relationships, the coopera- tive relationship between services could be calculated, and system makes recommendatio n with the relationship. Compared to [7], service group is calculated and formed according to the usage of services, it is a logical concept to help analysis the relationship between serv ices, but not a real entity existing in cloud. In the cloud environment, services that belong to different levels are often used together and form a service group, that brings about the situation that some lower-level services may become the fundamental member of service group, namely, this kind of service such as storage or platform is very necessary for most service group and can achieve a great many user’s requires, and a higher-level service would be a professional characteristics of the group, this kind of ser- vice is just used in parts of service groups and is neces- sary for particular users in some professional fields. There are two kinds of relationships between services, which can be different for the user’s current selection of services, and there are also large differences between recommending a base service when using a professional service and recommending a professional service when using a base service. So a two-way standard is introduced to distinguish the relationship of A to B and B to A when calculating the co operativ e relationship between services. On the other hand, user’s personalized interest should be taken into account while making recommendation. 3.1. Node Model Users and services are treated as nodes in the system. Open Access JSEA  A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services 625 User often needs a set of services instead of a single one to complete a task within a certain period of time. In Figure 1, User 1 U selected services A, B and C to achieve his task, user 2 U selected services C, D and selected services C, E. 3 In users’ history records, one user has chosen numbers of sets of service, so service group node was introduced to distinguish these sets and make it easy to analysis. In Figure 2, a service group includes some services, so the situation above could be described just like the structure in Figure 2, user 1 U used service group and , and user used group . U 1 SC 2 23 User Model: User is defined as a set which describes all users in the system. The user has a set i, defined as SC USC 123 ,,,,, i UUUUU i U DS ,, ,SC ,DSUSC SC ii mn , which describes all service groups that i had used. There is a vector QoS U ,,,abcd for each user to describe the user’s prefer- ence for stability, security, network quality and charge mode. Service Group Model: Service group is defined as Figure 1. Structure of users and services. Figure 2. Model of service group. a set 123 ,,,,, i SC SCSCSCSC, which describes all service groups in the system. Service Model: Service is defined as a set 123 ,,,,, i SSSSS, which describes all services in the system. The service group , has a set i, which is defined as i SC D ,,, iijk DSCSS, describes the mem- ber services that make up the group i.ki SC is defined as the relationship of i and k, it equals 1 when service i is one of members of service group k, there will have an edge connected between the i-th ser- vice node and k-th service group node. k is defined to record the number of members of service group k.ij SSC SSC NSC is defined to tell whether the i-th and j-th service are in the same service group or not. The relationship between services can be calculated only when they are in the same service group. 1, 0, i ki ik SD SD k ki (1) k i N (2) 1, ,1 0, ,0 ki kj ij ki kj k k (3) Cooperative Relationship between Services: Two services in one service group have two edges to connect. One is from i to j, another is from j to i. For the edge ij , there is a weight assigned to it, defined as SSij , means the cooperative relation ship from to i S S. ij is defined as follow: 1 1 ki kj kk ij ki k N (4) In the formula, 1 ki kjk N means the proportion for service S cooperates with i in all services that cooperate with i in the k-th group. S Sij shows the probability of service S cooperates with . i S 1 ij j (5) It is obviously that the relationship from i to S Sand the relationship from S to i are different. Since i and S S S may belong to different service grade or level, such as base services and professional services. When user selects a professional service, the recommen- dation system may give a base service with high proba- bly, because the relationship from the professional ser- vice to the base service should be higher. Contrarily, when user selects a base service, the system might be confused to decide which professional service should be Open Access JSEA  A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services 626 given because it does know user’s profession, and the relationship from the base service to a professional ser- vice should be lower. Similarity Between Users and Services: Vector rep- resentation is used to describe the QoS of services and users’ preference, given two vector x and y, using cos(x,y) multiplied by mode of y to rep resent the similar y from y to x. 112 2 1 , Sim ,cos , n ii i n i i y xy xyxy yy xy x (6) Result of Recommendation: The final result should combine the cooperative relationship with QoS similar. So the result is defined as SimSim . kijijkj ijkj Rf gab where a = 20 and b = 0.004, a and b are set to standard- ize relationship and similarity. 3.2. Recommendation Method The recommendation process is divided into four sec- tions as followed: Section 1, data processing and creating set S and U; Section 2, getting users’ preference; Sec- tion 3, obtaining users’ usage and relationship of services; Section 4, service recommendation. Detail discussing follows: 1) According to records, the set of users U and the set of services S will be counted, and then the set of service group SC will be added up. 2) According to the evaluation of the users to the ser- vices, the vector of users’ preference and Qos of services will be got. 3) The relationship between service groups and ser- vices and relationship between services will be calcu- lated. 4) Recommendation. The input is user k U and ser- vice i that the user has chosen. This process is divided into two steps; the first step is to calculate the top k ser- vices to which service i has higher cooperative rela- tion, to meet the user’s functional needs. This step must be done first, that means the service should match user’s functional needs first. And then the second step is to cal- culate the QoS similarity relation between these k ser- vices and the user to meet user’s non-functional needs. When the user has already selected more than one service, system should combine the result sets from each service according to the two steps above and give the final re- sults. S S 4. Simulation and Analysis 4.1. Data Creating Experimental data are created by a semi-random method, firstly, the services and their QoS are produced randomly; and users are produced as the same way. A vector is given to each user to show user’s preference, which will be only used in the next step to produce service groups. The rule in the step of producing group sets is that, A user selects several services from the service sets, and system will calculate the similarity of service QoS and user’s preference, then the top 2 - 4 services will be taken as a service group, the number of members of a group is got randomly fro m 2 to 4, and each user has a number of groups. Actually, when users select the services in actual life, there will be a number of services provided for the user, and user will select those which could fit user’s preference, this step of producing service group above has just simulated the process of users’ selection of ser- vices. The vector just given is only used in the step to produ ce gro ups , an d th e v e c tor of us er s’ pr ef e r en c e in the recommendation process will be recalculated in recom- mendation steps later. In the data producing process, the QoS of services that the user has chosen is similar to the user’s preference, so the service which has poor QoS would be eliminated. Meanwhile, services which have similar QoS will be selected by users who have similar preference, in other words, users who have similar preference will choose same services, these services will be combined as a group for many times, and the relationship of these ser- vices will be relatively high. The argument above is just to proof that, in the data created, the relationships be- tween services are not completely random, there are some services within which, every one of them has rela- tively high relationship to each other. So, the recom- mendation based on the date is m eaningf ul. 4.2. Results and Analysis The date have simulated a small cloud environment, data is created as follow: there are 100 users and every user has 100 service group records, each group has 2 to 4 members. In recommendation, the system will recom- mend to one user whom we call is the target user. To judge the recommendation is effective or not, the user’s record will be divided into two parts, one is the experi- mental group, the other part is the comparison group. The experimental group as the usage history record to get the target user’s preference. In each service group in the comparison parts, one or two services will be selected as the input, output is just the recommendation result, and it will be juxtaposed with the other services in this group. If one of the other services in the group is also a member of Open Access JSEA 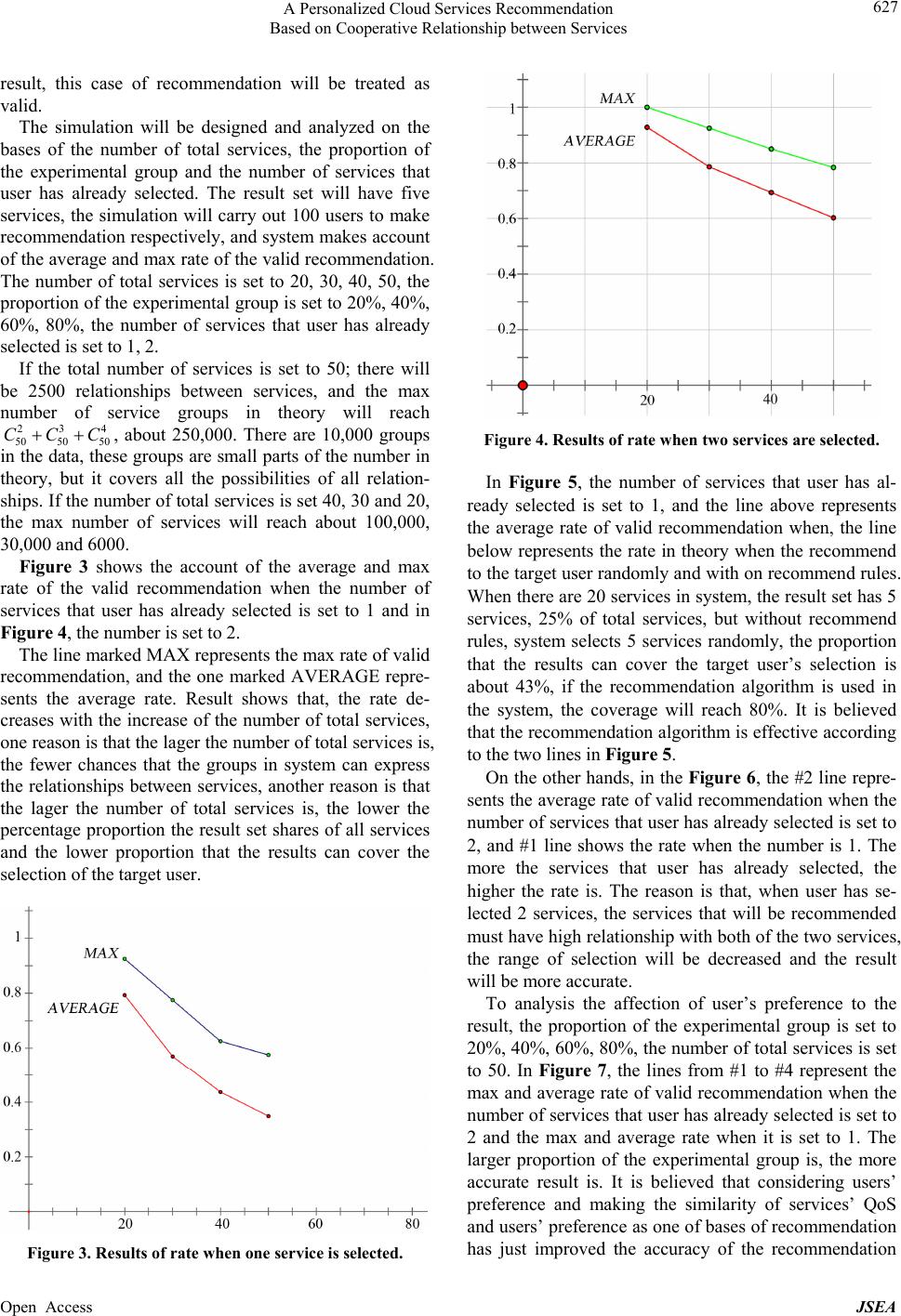 A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services 627 result, this case of recommendation will be treated as valid. The simulation will be designed and analyzed on the bases of the number of total services, the proportion of the experimental group and the number of services that user has already selected. The result set will have five services, the simulation will carry out 100 users to make recommendation respectively, and system makes account of the average and max rate of the valid recommendation. The number of total services is set to 20, 30, 40, 50, the proportion of the experimental group is set to 20%, 40%, 60%, 80%, the number of services that user has already selected is set to 1, 2. If the total number of services is set to 50; there will be 2500 relationships between services, and the max number of service groups in theory will reach , about 250,000. There are 10,000 groups in the data, these groups are small parts of the number in theory, but it covers all the possibilities of all relation- ships. If the number of total services is set 40, 30 and 20, the max number of services will reach about 100,000, 30,000 and 6000. 23 50 50 50 CCC 4 Figure 3 shows the account of the average and max rate of the valid recommendation when the number of services that user has already selected is set to 1 and in Figure 4, the number is set to 2. The line marked MAX represents the max rate of valid recommendation, and the one marked AVERAGE repre- sents the average rate. Result shows that, the rate de- creases with the increase of the number of total services, one reason is that the lager the number of total services is, the fewer chances that the groups in system can express the relationships between services, another reason is that the lager the number of total services is, the lower the percentage proportion the result set shares of all services and the lower proportion that the results can cover the selection of the target user. Figure 3. Results of rate when one service is selected. Figure 4. Results of rate when two services are selected. In Figure 5, the number of services that user has al- ready selected is set to 1, and the line above represents the average rate of valid recommendation when, the line below represents the rate in theory when the recommend to the target user randomly and with on recommend rules. When there are 20 services in system, the result set has 5 services, 25% of total services, but without recommend rules, system selects 5 services randomly, the proportion that the results can cover the target user’s selection is about 43%, if the recommendation algorithm is used in the system, the coverage will reach 80%. It is believed that the recommendation algorithm is effective according to the two lines in Figure 5. On the other hands, in the Figure 6, the #2 line repre- sents the average rate of valid recommendation when the number of services that user has already selected is set to 2, and #1 line shows the rate when the number is 1. The more the services that user has already selected, the higher the rate is. The reason is that, when user has se- lected 2 services, the services that will be recommended must have high relationship with both of the two services, the range of selection will be decreased and the result will be more accurate. To analysis the affection of user’s preference to the result, the proportion of the experimental group is set to 20%, 40%, 60%, 80%, the number of total ser vices is set to 50. In Figure 7, the lines from #1 to #4 represent the max and average rate of valid recommendation when the number of services that user has already selected is set to 2 and the max and average rate when it is set to 1. The larger proportion of the experimental group is, the more accurate result is. It is believed that considering users’ preference and making the similarity of services’ QoS and users’ preference as one of bases of recommendation has just improved the accuracy of the recommendation Open Access JSEA  A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services 628 Figure 5. Recommendation and randomly select ion re sults. Figure 6. Average rate when one and two services are se- lected. Figure 7. Results in different proportion of experimental group. according to the #1 and #3 lines which represent the max rate. When the proportion is relatively small, the result is not too low. It is friendly to new users who do not have too many history records and system cannot get too much information about their preference. 5. Conclusions Above all, a personalized recommendation for cloud ser- vices, which is based on usage history and the coopera- tive relationship of cloud services, is presented. Recom- mendation works according to the cooperative relation- ship among services to find out the functional comple- mentarity among them, and to recommend the results. Performance in the simulation proves that the recom- mendation works well in a small-scale cloud environ- ment with not so many services. One advantage of this recommendation is that, new users can get relatively ef- fective recommendation without so much information about preference. It remains future work to consider classification of us- ers and services when the cloud environment scale is larger. Classification should be considered from the point of view to distinguish users’ professionals and services’ functions. 6. Acknowlegements The work presented in this paper was supported by Na- tional Natural Science Foundation of China (Grant No. 61001118); Program for New Century Excellent Talents in University (Grant No. NCET-11-0592). REFERENCES [1] I. Cantador, M. Fe rnáandez and P. Castells, “A Collabo- rative Recommendation Framework for Ontology Evalua- tion and Reuse,” Universidad Autóonoma de Madrid, Spain, 2006. [2] G. Adomavicius and A. Tuzhilin, “Toward the Next Gen- eration of Recommender Systems: A Survey of the State- of-the-Art and Possible Extensions,” IEEE Transactions on Knowledge and Data Engineering, Vol. 17, No. 6, pp. 734-749. [3] J. B. Schafer, D. Frankowski, J. Herlocker and S. Sen, “Collaborative Filtering Recommender Systems,” Adap- tive Web, 2007. [4] Knowledge & Data Engineering Group (KDE), “Informa- tion Systems and Machine Learning Lab (ISMLL),” Tag Recommendations in Folksonomies, 2006. [5] J. G. Liu, T. Zhou, Y. C. Zhang and Q. Guo, “Degree Correlation of Bipartite Network on Personalized Rec- ommendation,” International Journal of Modern Physics C, Vol. 21, No. 1, 2010, pp. 137-147. http://dx.doi.org/10.1142/S0129183110014999 [6] C.-X. Jia, R.-R. Liu, D. Sun and B.-H. Wang, “A New Weighting Method in Network-Based Recommendation,” Physics A, Vol. 387, 2008, pp. 5887-5891. [7] W. F. Pan, B. Li, B. Shao and P. He, “Service Classifica- Open Access JSEA  A Personalized Cloud Services Recommendation Based on Cooperative Relationship between Services Open Access JSEA 629 tion and Recommendation Based on Software Networks,” Chinese Journal of Computers, Vol. 34, No. 12, 2011, pp. 2355-2369. [8] T. Zhou, J. Ren, M. Medo and Y.-C. Zhang, “Bipartite Network Projection and Personal Recommendation,” Physical Review E, Vol. 76, No. 4, 2007, Article ID: 046115. [9] X. Pan, G. S. Deng and J.-G. Liu, “Weighted Bipartite Network and Personalized Recommendation,” Physics Procedia, Vol. 3, No. 5, 2010, pp. 1867-1876. http://dx.doi.org/10.1016/j.phpro.2010.07.031 [10] Y. R. Gu and M. Chen, “One Tag Time-weighted Rec- ommend Approach on Tripartite Graphs Networks,” Computer Science, Vol. 39, No. 8, 2012, pp. 96-98. [11] S. Kang, S. Kang and S. Hur, “A Design of the Concep- tual Architecture for a Multitenant SaaS Application Plat- form,” Computers, Networks, Systems and Industrial En- gineering (CNSI), 2011 First ACIS/JNU International Conference on Digital 2011, pp. 462-467. [12] K. S. Gopalan and S. Nathan, “A Cloud Based Service Architecture for Personalized Media Recommendations,” International Conference on Next Generation Mobile Ap- plications, Services, and Technologies, 2011, pp. 19-24. [13] P. Bedi, H. Kaur and B. Gupta, “Trustworthy, Service Provider Selection in Cloud Computing Environment,” International Conference on Communication Systems and Network Technologies, 2012, pp. 714-718. [14] S. X. Yan, C. Q. Chen, G. P. Zhao and B. S. Lee, “Cloud Service Recommendation and Selection for Enterprises,” 6th International DMTF workshop on systems and Virtu- alization Management (SVM2012)/CNSM, 2012, pp. 431-433. [15] S. Bardhan and D. Milojicic, “A Mechanism to Measure Quality-of-Service in a Federated Cloud Environment,” Federated Clouds’12: Proceedings of the 2012 Workshop on Cloud Services, 2012, pp. 19-24. [16] W. Y. Zeng, Y. L. Zhao and J. W. Zeng, “Cloud Service and Service Selection Algorithm Research,” GEC’09: Proceedings of the first ACM/SIGEVO Summit on Ge- netic and Evolutionary Computation, ACM, 2009, pp. 1045-4048.
|