Paper Menu >>
Journal Menu >>
 J ournal o f A pp http://dx.doi.or g Copyright © 2 0 EPFI A I ABSTRA C The fundame n fication meth o or being exte n for short) is p simultaneous l renewing ide n p rogram. Ap p ment results o and support o n Keywords: P 2 1. Introdu c P2P technolo g net, which us makes Intern e edge. Recent s traffic is attri b rent and eDo n [1]. In this pap e termined by source and d e and 64 seco n traffic identifi transport laye r short), appli c method (f sig f o ristic identifi c chine learnin g After the inv a attention to f s to identify th e flow attribute s P2P applicati flow characte r classifier to i d [9,10]. Besid e tion methods, cations, new i ing. Thus, cu r p lied Mathemat i g /10.4236/jamp . 0 13 SciRes. A : Ext e I nstitute of Co m Email: xubo8 2 C T nt of managin g o ds are prese n n ded fast to s u roposed. In o r l y, and obtain s n tification met h p lying policy m o f running the n line renew P 2 2 P; Flow Iden c tion g y is one of th e es the idle re s e t computing s tudies show t h b uted to P2P a n key traffic is o e r we define f 5-tuple (sou r e stination port , n ds timeout is cation metho d r port based i d c ation layer s o r short), trans p c ation method g based identif i a lidation of f p i g , which uses e application s , statistics an on[7,8]. f ML c r istics of diffe r d entify the a p e s, there are a etc. As the d e i dentification m r rent P2P flo w i cs and Physics , .2013.14011 P u e nsible Bo X u m mand Informa t 2 0@163.com, L g P2P traffic i n ted nowaday s u ppor t new me r der to identif y s the highest e h ods is desig n m echanism, id prototype sys t 2 P identificati o tification; Ar c e most excitin g s ources in net w pattern fro m h at more than a pplications, o o f 80% of the f low as bidire c r ce and dest i , and transpor t adopted [2]. d s can be divi d d entification m ignature base p ort layer beh a (f behavior for s i cation metho d p ort [3], resear c the packet p a accurately [3- d behavior fe a c onstructs cla s r ent protocol, a p plications of lso crawlers b e velopment of m ethods will k w identificatio n , 2013, 1, 56-62 u blished Online O P2P Fl o u , Bing Li, C t ion System PL A ibing781@163. Recei v i s identifying v , there are no thod. In this w y many specif i fficiency via a n ed, which ca n entification m t em show us t h o n methods a n hitecture; Pol i g areas of Int e w ork edge, a n m centralized t 60% of Inter n f which BitT o total P2P traf f c tional flow d nation addre s t layer protoc o Generally P 2 d ed into 4 typ e m ethod (f port fo d identificati o a vior based he u s hort), and m d (f ML for shor t c hers pay mo r a yload signatu r 6]. f behavior us e a tu r e to identi f s sifier with t h a nd then use t h unknown flo w b ased identific new P2P app l k eep on eme r g n methods ha v O ctobe r 2013 ( h o ws Id e C hao Hu, G u A University of com, Huchao1 0 v e d August 201 3 v arious P2P fl ideas for eith e w ork, an exten s i c P2P flows, E a djusting thei r n extend new i m ethods can be h at EPFIA co u n d manage the m i cy Schedule e r- n d t o n et o r- f ic e- s s, o l) 2 P e s: fo r o n u - a- t ). r e r e e s f y h e h e w s a- l i- g - v e the fol l P2P ap p hard t o P2P ap system softwa r modif y ing or m We p tificati o impro v sequen c signin g online, functio n mecha n thod c a Moo cation l the ni n order o applic a p act o f p erfor m cation f identifi tion m e tify un k The Sectio n h ttp://www.scir p e ntifica t u omin Zhan g Science and Te c 0 07@163.com, z 3 ows accuratel y er integrating s ible P2P flo w E PFIA uses m r identificatio n dentification m updated, star t u ld effectivel y m remotely. l owing probl e p lications nee d o deploy syst e plications; se c is inflexible, r e (even redes i y some new i d m aintaining id e p ropose EPFI A o n methods. E v ing identific a c e of identif y g a mechanis m which can e n without re c n ism, the upd a a n be carried o u re and Papagi a l ayer payload t n e identificati o o f implementa t a tion of each fl f the compone n m ance. Most o f eatures, and s t cation metho d e thod under e x k nown traffic. remainder of n 2 pro p oses t p .org/journal/ ja m t ion Ar g c hnology, Nanj i z hang_gmwn@ 1 y . Although m these indepen w s identificati o m any different n sequence. A n m ethod witho u t ed and halted y promote the p ms: firstly, i d d one kind of d e m that can i d c ondly, the str u and it needs i gn system ar c d entification m e ntification sy s A to assemble m E PFIA has t h tion efficienc y y ing different m to update i e xtend the P 2 c ompile the s a te, start, and s u t remotely. a nnaki used p o t o identify P2 P o n methods b a t ion complexi t fl ow, and pay n n t of traffic o n f current wor k t udied the acc u d s, they cannot x isting archite c this paper is t he architectu r m p ) chitect u i ng, China 1 63.com m any P2P flo w dent methods o n architectur e identification n online mech a ut compiling t h remotely. Th e p erformance o d entifying one d evice, this w i d entify many u cture of iden t recompile th e c hitecture) to e m ethods; thirdl y s tem is very d i m any P2P tra f h e following y via optimi z P2P applicati i dentification 2 P flow iden t oftware; usin g s top identific a o rt numbers a n P flow [6]. Th e a sed on the a s t y so as to ide n o attention t o n identificatio n k s focus on P 2 u racy and effi c extend new i d c ture, and can n organized as r e of EPFIA JAMP u re w s iden t i- together e (EPFIA methods a nism of h e whole e expe r i- o f system kind of i ll be too kinds of t ification e system e xtend or y , updat- i fficult. f fic iden- features: z ing t he i ons; d e- methods t ification g policy a tion m e- n d appli- e y sorted s cending ntify the o the im- n system 2 P appli- c iency of d entifica- n ot iden- follows: and dis-  B. XU ET AL. Copyright © 2013 SciRes. JAMP 57 cusses the impact of identification methods running se- quence on system performance. Section 3 presents an online identification methods updating mechanism. Sec- tion 4 studies the method of using policy mechanism to maintain and update identification system. Section 5 va- lidates the feasibility of EPFIA and tests its performance. Finally, Section 6 summarizes the whole paper. 2. Design of EPFIA 2.1. Design Principle The main work process of EPFIA is as follows. Firstly, the packet capturer module is deployed at the bottom of EPFIA, which captures packets from the physical link, and filters packets that do not use TCP/UDP (Since P2P application usually using TCP/UDP transport protocol), and then submits packets to system identification modules in uniform format and style. In the paper, we use identifi- cation module denote the concrete implement of identifi- cation method. Using the uniform format so that it has packet information needed by any identification module, and using the uniform style because some identification methods only need one packet in a flow while others need a sequence of successive packets. Besides, the uniform format also makes all identification modules can work with the same packet capturer module. Since capturing packets from physical link consumes a large amount of system resources, it is of great important to use a uniform packet capturer module. EPFIA handles packet based on flow state, which can be classified into two kinds: known and unknown. Known means a flow belongs to a kind of P2P or non-P2P appli- cation that has been identified, and it is of no need to identify it any more. While unknown means we need the identification module to handle the packet. Suppose Λ is the packet information, and its format is shown in Figure 1. The flow identifier ΛflowID is calculated using function CreateHash based on the first 5 field in Figure 1, which can be used to determine which flow the packet belongs to, and then determine whether the packet belongs to un- known. Finally, the unknown packet should be handled by many P2P identification modules, and change the flow state to be known. During this process, we can use fport to identify non-P2P flow based on ΛsrcPort and ΛdstPort, and use fsig to identify P2P flow that has application layer sig- Figure 1. Format of packet information. nature. For other unknown flows, we should design cor- responding identification method to identify them. To achieve the goal of identifying many P2P applica- tions in a system, we need to run many P2P identification modules simultaneously, update these modules frequently, and manage these modules remotely. As an extensible architecture for identifying P2P applications, we should focus on the following questions when designing EPFIA: 1. Whether these P2P flow identification modules should be run randomly or in some fixed sequence? If there are some relationships between efficiency and identi- fication sequence, what are the relationships? 2. Since new identification methods keep on emerging, can we extend some new identification methods con- veniently without recompile the existing program? 3. If we want to remotely update, start or stop a P2P identification module running at somewhere in the network, is there a good implementation mechanism? 2.2. Best Running Sequence of Identification Modules EPFIA should call many specific identification modules so as to implement the identification of unknown flow. By changing the running sequence of many different identification modules, we can improve the whole work- ing efficiency. Suppose p(x) represents the computation cost of iden- tification module x when identifying a flow, and fport cost is p(x1), fsig cost is p(x2), fbehavior cost is p(x3), fML cost is p(x4). Based on the identification principle we know the following inequation hold on: p(x1) < p(x2) < p(x3) < p(x4) (1) During time T, if there are F flows, and the percentage of flows that identified by identification module x is fx, we give the following definitions: Definition 1: Identification Module Running Sequence (Identification Sequence in short). Identification Se- quence represents the set of identification modules and their running sequence. If we use Rn to represent the Identification Sequence of n different modules, then Rn={r1→…→ri→…→rn}, in which ri represents the ith running modules. Definition 2: System Identification Cost (Cost in short): The cost of identification sequence Rn when iden- tifying F flows in time T. We use POWER(Rn)T represent Cost. Definition 3: Priority Relationship P of Identification Modules (Priority for short). For any two identification modules in Rn, P represents the running sequence that makes the Co st smaller. Suppose the Identification Se- quence Rn={r1→…→x→…→y→…→rn}, Rn ’={r1→…→y→…→x→…→rn},  B. XU ET AL. Copyright © 2013 SciRes. JAMP 58 if and only if POWER(Rn ’)T < POWER(Rn)T, we say y and x have Priority P, and note it as yPx. Definition 4: Running Efficiency of Identification Module x (Running Efficiency for short). The ratio be- tween the number of flows identified by x and the com- putation cost of x in time T is defined as Running Effi- ciency of x, which is represented as E(x) = fx*F/p(x). Suppose F flows belong to m applications, and there are n identification modules that can identify each flow accurately. These modules have Priority P and we can adjust their running sequence randomly, then we have the following lemma. Lemma 1: There is a best Identification Sequence Rn that makes the POWER(Rn)T minimum. Proof: For the n identification modules, there is a se- quence R’ n that ' (, ) n x yxy RxPy . If we ex- change any two identification modules in R’ n and form R’’ n, from definition 3 we know POWER(R’’ n)T > POWER(Rn ’)T. That is, there is a best Identification Sequence R n, in which any two identification modules have Priority P, so that POWER(Rn)T is minimized. Theorem 1: Identification modules that have high Running Efficiency have high Priority, that is (,() ()) n x yxy RExEyxPy . Proof: Suppose E(x) < E(y), x and y have the Priority P. Since the Running Efficiency of y is higher than that of x, by running y first we can reduce the number of un- known flows, and thus reduce the system identification cost, which conflicts with the assumption that the Prior- ity of x is higher than that of y. Thus, when running more than one identification module, we should adjust their running sequence according to their Running Efficiency so as to reduce Cost. 2.3. Architecture of EPFIA Suppose p(x2) = m2p(x1), p(x3) = m3p(x1), p(x4) = m4p(x1), then 1 < m2 < m3 < m4 (2) Non-P2P traffic accounts for about 30% of the total Internet traffic, and most of them use fixed ports to communicate with each other [1], thus we can use port number to identify them. The traffic of BitTorrent and eDonkey takes about 80% of total P2P traffic, and more than 73% and 83% of them do not encrypt their payload, thus we can use application layer signature to identify them. Other types of P2P application flow have no port and application layer payload feature, and thus we should design specific identification methods for them. Take the former discussion into consideration, the efficiency of fport is E(x1) ≈ 0.3*F/ p(x1), and the efficiency of fsig is E(x2) ≈ 0.41*F/p(x2)= 21 0.41 () F mpx , and the efficiency of fbehavior + fML is E(x3 + x4)≈ 34 0.29 () () F px px > 41 0.29 () F mpx . Each identification module identifies the application of flow according to Λ, and we can use the number of packet to estimate the computation cost of a special iden- tification module. Based on the principle of different identification methods, we know m4 ≥ m3 ≥ 3, and thus E(x1) > E(x2) > E(x3 + x4) (3) As a result, we can get the best efficiency by using the following Identification Sequence: firstly using fport to identify non-P2P flows, and then using fsig to identify un-encrypted P2P flows, finally using other special me- thods to identify the remainder P2P flows. Observed that the identification is based on flow, and as the process of identification, the percentage of identi- fied flows will keep on increase. If there are M packets in a new flow fnew, and an identification module can identify the application of fnew based on the first n packets, thus the remainder M-n packets will need not to be identified any more. Generally M >> n, we can increase the identi- fication efficiency by identifying which flow the M-n packets belong to. Thus we design a flow differentiation module, which identifies whether a coming packet be- longs to a known or an unknown flow, and we only han- dle packets that belong to unknown flows. Experiment results show that this method can filter about 98% pack- ets, and thus decreasing the identification cost effective- ly. Based on the upper discussion, we designed an ex- tensible P2P flow identification architecture, which is shown in Figure 2. EPFIA uses flow identifier ΛflowID as the address of Hash-Table item, and this address is also used as the first address of storing active flow information flow-key. flow-key = {source IP address srcIP, source port srcPort, destination IP address dstIP, destination port dstPort, Packet capturer 1000 Mb/sNetwork lin k Packet traffic 10 0 / Port identification module Identification Sequence Rn Communication module Hash table Analysis syste m Config file Flow differentiation module Signature identification module Policy system Figure 2. Extensible P2P flow identification architecture.  B. XU ET AL. Copyright © 2013 SciRes. JAMP 59 transport protocol Proto, flow state State }, in which State ∈{−1, 0, P2P_ID }, and “−1” represents unknown flow, “0” represents non-P2P flow, and “P2P_ID” represents the P2P application code defined by us. In addition, each flow has a counter, which is used to record the number of packets identified for unknown flows. When counter is larger than a threshold Φ, we change the state of that corresponding flow to be a non-P2P flow. We also use [PORT]std to represent standard network service ports, and use [SIG]P2P to represent the set of specific P2P application signatures. 3. Identification Program Online Updating Mechanism In order to add new identification module, maintain and update current module and adjust the running sequence of different modules conveniently, EPFIA uses the form of plug-in to manage different identification modules. EPFIA stores all identification modules in a plug-in da- tabase, and stores the running sequence Rn in a policy database. Figure 3 shows the format of plug-in stored in policy database. In which “Priority” is a number that defines the plug- in’s running sequence; and “P2P application code” de- notes the P2P application that this plug-in can identify; and controller uses “Store path” and “Plug-in name” to locate the plug-in, and use “Main control function” to run this identification module. Figure 4 shows the online updating mechanism of EPFIA. During the initialization phase, the main control mod- ule accesses the policy database to get Rn, and then stores all plug-in information in the memory using list structure, which is sorted by priority. During the identification phase, the controller calls different identification mod- ules to handle each packet according to the priority se- quence. EPFIA updates identification module by maintaining the plug-in database, and adds new identification module Figure 3. Format of plug-in stored in policy database. Figure 4. Online updating mechanism of EPFIA. as well as adjusts the running sequence of different iden- tification modules by handling the list, thus it avoids re- compiling the program to implements such functions. 4. Policy Mechanism EPFIA uses policy mechanism to support updating, starting and stopping identification modules remotely. The policy is divided into two kinds: manually and au- tomatically. The manual policies are setup by adminis- trator, which include identification modules running se- quence Rn and parameters; automatic policies are gener- ated using policy control language by EPFIA during the system running time, and they optimize the system effi- ciency by adjusting Rn dynamically. Figure 5 shows the EPFIA policy mechanism. In EPFIA, the controller provides two access interfac- es: one is the plug-in database access interface FAP, and the other is the policy database access interface PAP. Administrators can access FAP and PAP through control center. The controller stores the received plug-in in the plug-in database, and stores the received policy in the policy database, and then updates Rn according to the new policy. According to Lemma 1 and Theorem 1, the running sequence of P2P flow identification modules can affect the efficiency of EPFIA. Though administrators can se- tup the running sequence of identification modules, it is very difficult to estimate the Running Efficiency of each identification module accurately and adjust their Priority immediately. EPFIA uses automatic policy and adjusts the module Priority dynamically. EPFIA determines the relative computation cost mx of program x according to the number of packets x needs to handle. F(x)T represents the number of flows x identified during time T, and we use E(x)T = F(x)T/mx to represent the efficiency of x dur- ing time T. The automatic control policy computes the current identification efficiency E(x)current of x based on E(x)T and the old identification efficiency E(x)old. E(x)current = (1 − ε)·E(x)T + ε· E(x)old (4) In Equation (4), ε is a decimal fraction between 0 and 1, which is used to control the sensitivity of efficiency Figure 5. EPFIA policy mechanism.  B. XU ET AL. Copyright © 2013 SciRes. JAMP 60 variation. The automatic control policy calculates the current identification efficiency E(xi)current of module xi(1 ≤ I ≤ n) periodically, and determines the Priority ac- cording to E(xi)current. Our experiment results show that the automatic control policy in EPFIA can adapt to the network traffic variation and increase the whole identifi- cation efficiency. 5. Experiments and Analysis To validate the upper analysis, we developed the proto- type system of EPFIA named P2P-Analyzer, which in- cludes two P2P flow identification programs: one for UDP based Skype voice flow (Skype_Detection, SD), and the other for PPLive video flow (PPLive_Detection, PD). We test the performance of P2P-Analyzer for a long while in the campus network of PLAUST, and following is the typical experiment result and its analysis. 5.1. Experiment Environment and Method The experiment environment of P2P-Analyzer is shown in Figure 6. The campus network connects to the CER- NET through 100 Mbps fiber, and the experimental hosts have Intel Core2 CPU with 2.33 GHz frequency, and 2 GB memory. In the campus network we install Skype, PPLive and BitTorrent client, which run randomly during the experiment. The running information such as com- munication begin time, number of communications and download file size are also recorded manually. The Tcpdump is running at the mirror port of the switch so as to capture the packet information with 50 bytes applica- tion layer payload. The P2P-Analyzer is also run to iden- tify P2P flow automatically, and send the identified P2P flow information flow-keys to P2P-Looker to handle. P2P-Looker is the software that can analyze multi-type P2P flow information, so we can decrease the influence of analyzing on P2P-Analyzer performance. Besides, we also setup a control center so as to manage P2P-Analyzer remotely. In order to compare and analyze the performance of Figure 6. Experiment environment of P2P-Analyzer. P2P-Analyzer, we firstly analyze the P2P flow informa- tion manually using data captured by Tcpdump, and use this result as the ground truth. Then compare it with the results identified by P2P-Analyzer. The counter is set in each module of P2P-Analyzer to record packets handled. For every 5 minutes the CPU usage of each module is calculated. 5.2. Experiment Results and Analysis We analyze two typical experiment results carried out at different time. The packet information collected by Tcpdump is stored in two trace files, and the manual analysis result is shown in Table 1. Others include HTTP, FTP, DNS, Flash, FTP, ICMP, IMAP, MSN, POP, QQ, SMTP as well as unknown traffic, of which HTTP and Flash is more than 85%. In the first experiment, SD runs in the first two hours, and PD is called by policy in the last two hours. We se- tup Φ = 10 (the maximum number of packet that SD needs to identify Skype). The counter is outputted every hour so as to examine the performance of EPFIA. The result is shown in Table 2, from which we can see that the packet capturer filters 1% non TCP/UDP traffic, and the flow differentiation module filters 98% of the total packet, which decrease the load of identification modules dramatically. The number of unknown packet is de- creased after calling PD. In addition, PD can identify PPLive flow before the number of packet reaches Φ, and thus decreases the load of other identification modules further. Figure 7 shows the CPU usage during the first expe- riment. In the first two hours when running SD, the av- erage CPU usage is 11.3%, and in the last two hours when running SD and PD together, the average CPU usage is 10.1%. From this we see that when adding new module, the usage of CPU can decrease because of the Running Efficiency of identification modules. In the second experiment, we setup the relative com- putation load of PD and SD according to the number of 16 11 1621 2631 3641 4648 0 10 20 30 40 50 60 70 80 90 100 Time () CPU Usage% Figure 7. CPU usage information during the first experiment. 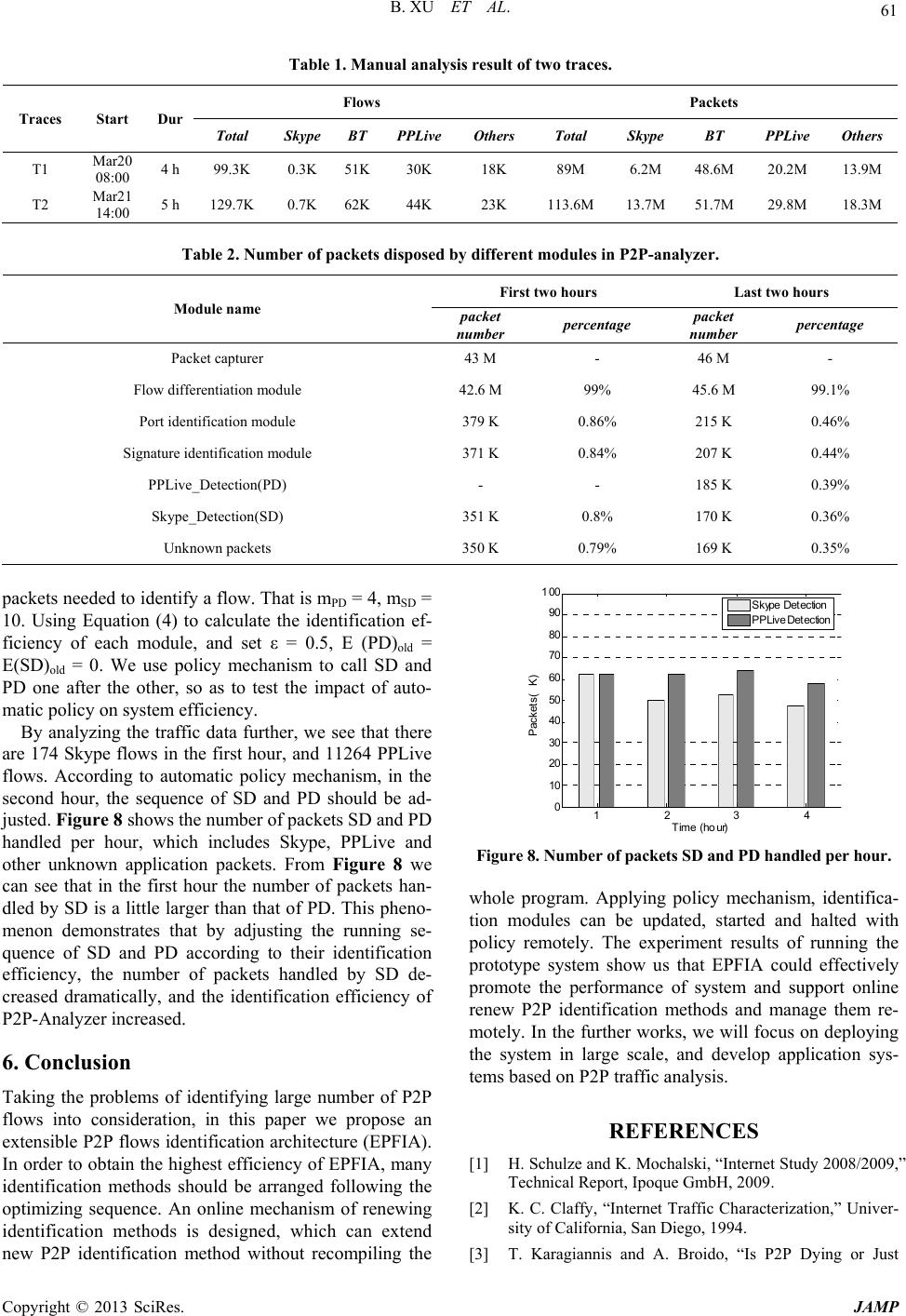 B. XU ET AL. Copyright © 2013 SciRes. JAMP 61 Table 1. Manual analysis result of two traces. Traces Start Dur Flows Packets Total Skype BTPPLive Others Total Skype BT PPLive Others T1 Mar20 08:00 4 h 99.3K 0.3K 51K30K 18K 89M 6.2M 48.6M 20.2M 13.9M T2 Mar21 14:00 5 h 129.7K 0.7K 62K44K 23K 113.6M 13.7M 51.7M 29.8M 18.3M Table 2. Number of packets disposed by different modules in P2P-analyzer. Module name First two hours Last two hours packet number percentage packet number percentage Packet capturer 43 M - 46 M - Flow differentiation module 42.6 M 99% 45.6 M 99.1% Port identification module 379 K 0.86% 215 K 0.46% Signature identification module 371 K 0.84% 207 K 0.44% PPLive_Detection(PD) - - 185 K 0.39% Skype_Detection(SD) 351 K 0.8% 170 K 0.36% Unknown packets 350 K 0.79% 169 K 0.35% packets needed to identify a flow. That is mPD = 4, mSD = 10. Using Equation (4) to calculate the identification ef- ficiency of each module, and set ε = 0.5, E (PD)old = E(SD)old = 0. We use policy mechanism to call SD and PD one after the other, so as to test the impact of auto- matic policy on system efficiency. By analyzing the traffic data further, we see that there are 174 Skype flows in the first hour, and 11264 PPLive flows. According to automatic policy mechanism, in the second hour, the sequence of SD and PD should be ad- justed. Figure 8 shows the number of packets SD and PD handled per hour, which includes Skype, PPLive and other unknown application packets. From Figure 8 we can see that in the first hour the number of packets han- dled by SD is a little larger than that of PD. This pheno- menon demonstrates that by adjusting the running se- quence of SD and PD according to their identification efficiency, the number of packets handled by SD de- creased dramatically, and the identification efficiency of P2P-Analyzer increased. 6. Conclusion Taking the problems of identifying large number of P2P flows into consideration, in this paper we propose an extensible P2P flows identification architecture (EPFIA). In order to obtain the highest efficiency of EPFIA, many identification methods should be arranged following the optimizing sequence. An online mechanism of renewing identification methods is designed, which can extend new P2P identification method without recompiling the 1 23 4 0 10 20 30 40 50 60 70 80 90 100 Ti me (h ou r) Packets( K) Skype D e tect i on PPLi ve D etect io n Figure 8. Number of packets SD and PD handled per hour. whole program. Applying policy mechanism, identifica- tion modules can be updated, started and halted with policy remotely. The experiment results of running the prototype system show us that EPFIA could effectively promote the performance of system and support online renew P2P identification methods and manage them re- motely. In the further works, we will focus on deploying the system in large scale, and develop application sys- tems based on P2P traffic analysis. REFERENCES [1] H. Schulze and K. Mochalski, “Internet Study 2008/2009,” Technical Report, Ipoque GmbH, 2009. [2] K. C. Claffy, “Internet Traffic Characterization,” Univer- sity of California, San Diego, 1994. [3] T. Karagiannis and A. Broido, “Is P2P Dying or Just  B. XU ET AL. Copyright © 2013 SciRes. JAMP 62 Hiding?” IEEE GLOBECOM 2004, Dallas, Texas, 29 November-3 December 2004, pp. 1532-1538. [4] S. Sen and O. Spatscheck, “Accurate, Scalable In-Network Identification of P2P Traffic Using Application Signa- tures,” WWW2005, New York, USA, 17-22 May 2004, pp. 512-521. [5] M. Roughan and S. Sen, “Class-of-Service Mapping for QoS: A Statistical Signature-Based Approach to IP Traf- fic Classification,” IMC 2004, Taormina, Italy, 25-27 October 2004, pp. 135-148. [6] A. Moore and K. Papagiannaki, “Toward the Accurate Identification of Network Applications,” PAM 2005, Boston, USA, 31 March-1 April 2005. [7] T. Karagiannis and A. Broido, “Transport Layer Identifi- cation of P2P Traffic,” In IMC’04, Taormina, Italy, 25-27 October 2004, 14p. [8] T. Karagiannis and K. Papagiannaki, “BLINK: Multilevel Traffic Classification in the Dark,” SIGCOMM’05, Phil- adelphia, USA, 21-26 August 2005, 12p. [9] L. Bernaille and R. Teixeira, “Early Application Identifi- cation,” The 2nd ADETTI/ISCTE CoNEXT Conference, Lisboa, Portugal, December 2006. [10] M. Crotti and M. Dusi, “Traffic Classification through Simple Statistical Fingerprinting,” SIGCOMM Computer Communication Review, Vol. 37, No. 1, 2007, pp. 5-16. http://dx.doi.org/10.1145/1198255.1198257 |