W. Z. LI ET AL.
Copyright © 2013 SciRes. CN
Although those two algorithms have been implemented
by equipment manufacturers, with high accuracy if ade-
quate enough network parameters are collected, their in-
dex values are not very applicable to monitor the QoE of
voice service and network quality. That’s because the
major parameters such as FER, BER, frame loss and so
on which have a great impact on QoE can’t be real-time
acquired by operators in the GSM signaling monitoring
platform. Besides, the speech index values of SQI and
VQI cannot be compared in the network monitoring and
optimization because of their private interfaces by dif-
ferent manufacturers. The purpose of this paper is to solve
the existing problems by proposing a novel QoE mea-
suring algorithm especially for GSM network. The algo-
rithm inputs are specific network parameters collected in
signaling monitoring platform from commercial GSM net-
work of China Mobile. Multiple Linear Regression (MLR)
based on least squares is adopted to further investigate
the relationship between network parameters and QoE of
voice service. All of these features make it possible that
the real-time algorithm with low complexity is suitable
for monitoring QoE of v oi c e s e r vi c e by opera tors.
2. Measurement of QoE of Voice Service
Based on GSM Network Parameters
2.1. Thinking of Measurement Algorithm
The purpose of this algorithm is to measure QoE of voice
service in real time by GSM network parameters. There-
fore, two conditions should be satisfied: network para-
meters must be obtained in real time; a mapping model
from network parameters to speech quality should be es-
tablished.
In GSM network, Measurement Repor t (MR) is one of
the main foundations to assess the quality of radio envi-
ronment. The MR signaling is transmitted every 480ms
in traffic channel (470ms in signaling channel), including
Received S ignal Qua lity (Rx Qual), Re ceived Signal Level
(RxLev), handing over, hopping, speech coding mode and
etc. Therefore, selecting MR as the access of network pa-
rameters can not only express the quality of current radio
link, but also requires little cost to transform current net-
work. Considering the following conditions: time for hu-
man ear to percept voice, PESQ algorithm proposing the
assessed object includes at least 3.2 s speech [7] and the
quantity of MR demanded by measuring algorithm and
the efficiency of data collection in commercial network,
the time granularity of measuring algorithm used in this
paper is set as 4.8 s finally.
The next step is to obtain the speech quality used for
data modeling corresponding to network parameters. The
specific approach is to record the voice sample corres-
ponding to a set of network parameters in time, and then
assess the speech quality with PESQ a lgor ithm . T he model
mapping from network parameters to voice quality adopts
the Multiple Linear Regression method which takes the
advantage of low complexity and high accuracy.
2.2. Obtaining Network Parameters
To reflect the status of current n e two rk more r e alistically,
both the model training and testing use data are collected
from the commercial network. In order to accurately meas-
ure the influence to speech quality caused by radio link
parameters, we ca ptured t he net work param eters and speech
data using the way of cell phone calls landline.
A communication circuit includes wired links and wire-
less links, of which the wireless links are the key aspects
that affect speech quality while the wired parts having
less effects on speech quality are negligible. Meanwhile,
the algorithm is to assess the voice quality of one single
side of the radio links because most of the parameters
reflecting the network q uality could not be transmitted to
the other side of core network (MSC). Accordingly, the
method of obtaining network parameters and speech sam-
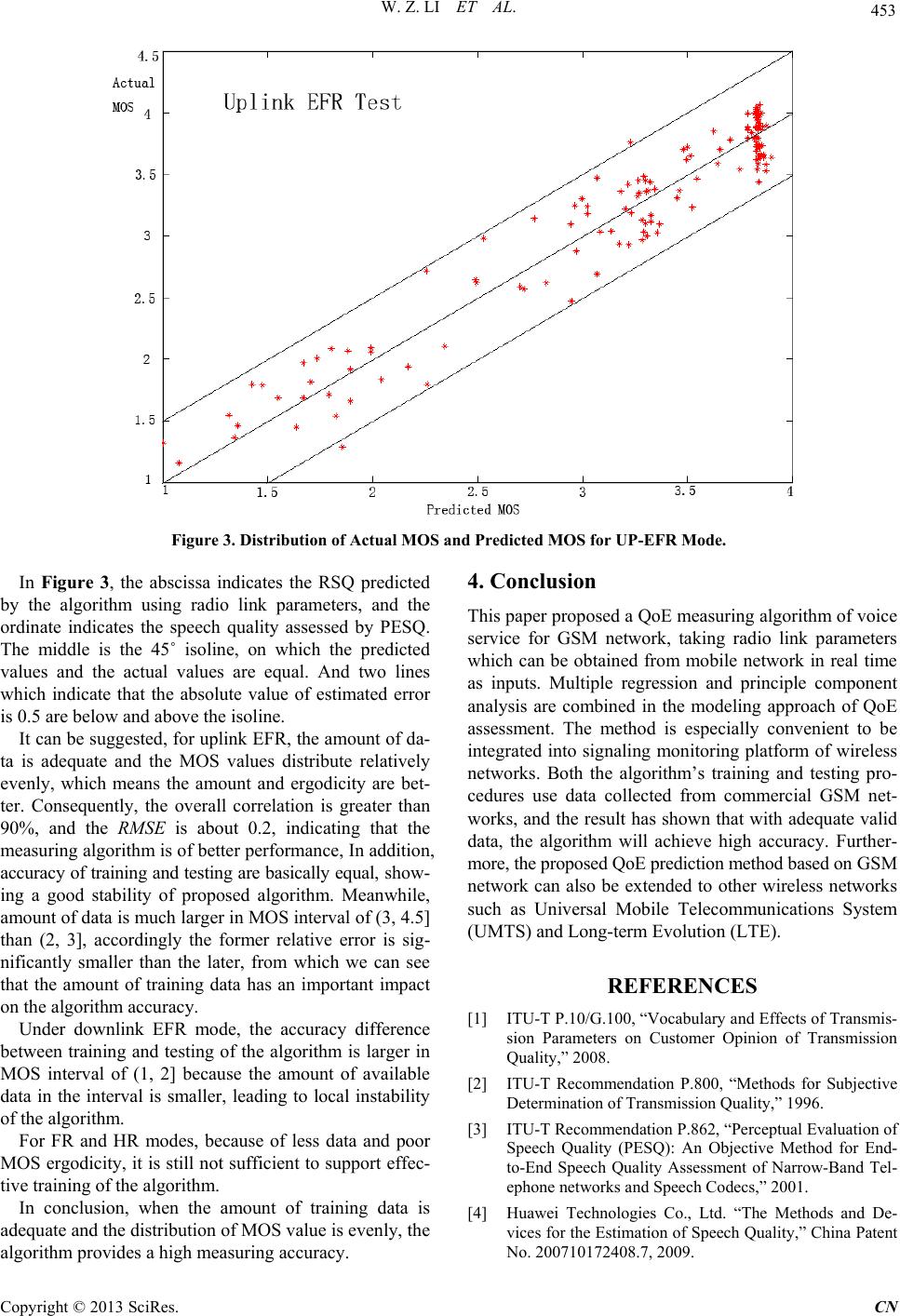
ples is expressed in Figure 1.
The transmissions of uplink speech and downlink speech
are relatively independent process. Therefore, the speech
quality of uplink or downlink is affected by uplink or
downlink respectively. The uplink parameters are meas-
ured by the Base Transceiver Station (BTS) of the net-
work while the downlink parameters are measured by the
user terminal and then reported to network by Measure-
ment Report signaling of Um interface. In summary, both
the uplink and down link parameters are collected by sig-
naling monitoring platform of Base Station Controller
(BSC).
Figure 1. Model of data collection.