Journal of Software Engineering and Applications
Vol.08 No.02(2015), Article ID:54060,10 pages
10.4236/jsea.2015.82007
Content-Based Image Retrieval Using SOM and DWT
Ammar Huneiti, Maisa Daoud
Department of Computer Information Systems, the University of Jordan, Amman, Jordan
Email: a.huneiti@ju.edu.jo, maysa_taheir@yahoo.com
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 23 January 2015; accepted 12 February 2012; published 13 February 2015
ABSTRACT
Content-Based Image Retrieval (CBIR) from a large database is becoming a necessity for many applications such as medical imaging, Geographic Information Systems (GIS), space search and many others. However, the process of retrieving relevant images is usually preceded by extracting some discriminating features that can best describe the database images. Therefore, the retrieval process is mainly dependent on comparing the captured features which depict the most important characteristics of images instead of comparing the whole images. In this paper, we propose a CBIR method by extracting both color and texture feature vectors using the Discrete Wavelet Transform (DWT) and the Self Organizing Map (SOM) artificial neural networks. At query time texture vectors are compared using a similarity measure which is the Euclidean distance and the most similar image is retrieved. In addition, other relevant images are also retrieved using the neighborhood of the most similar image from the clustered data set via SOM. The proposed method demonstrated promising retrieval results on the Wang Database compared to the existing methods in literature.
Keywords:
Image Retrieval, SOM, DWT, Feature Vector, Texture Vector

1. Introduction
Content-Based Image Retrieval (CBIR) is a technique to search and index images in a large collection database based on their visual contents like colors, textures, shapes or spatial layouts instead of using tags or other descripting metadata keywords that might associate with the images in the database [1] .
Typically, most CBIR systems work by extracting one or more multi-dimensional vectors from each image in the database, this process is done in a posterior step to start retrieving. At query time, the same vectors are usually extracted from the query image and a similarity based function is used then to quantify the amount of difference between the query image vector and other images vectors in the database. Images that have similar vectors to the query one are finally retrieved as a result.
Content Based Image Retrieval finds its applications in many domains such as medical diagnostics, GIS and military applications, pattern recognition, computer vision and many others [2] . However, in most applications CBIR systems are basically depending on extracting some features, i.e. characteristics that can capture certain visual properties of an image either globally for the entire image or locally for its regions [3] [4] and deciding the features that can effectively discriminate images and help in matching the most similar ones is the most challenging issue in CBIR systems.
Color features are widely used in CBIR systems as they are independent of image size and orientation [5] . They are usually extracted from different color spaces, e.g. RGB, HSV, YCbCr, by computing the color histogram, color moments or dominant colors. Zhang et al. [6] calculated the color histogram in the HSV color space then he quantized the Hue and Saturation into eight bins while the Value channel was quantized into four bins. Color histograms don’t capture the spatial relationships of color regions, so they don’t robustly match similar image regions.
Stricker and Orengo [7] suggested using the first three color moments (mean, variance and skewness) for each color channel of the HSV color system in order to store each image as a color vector with (9) features. This technique proved its efficiency in matching similar images better than calculating the color histogram.
Liu et al. [8] extracted the dominant colors by segmenting images into regions, obtaining the histogram for every region and taking the bin with the maximum size as a dominant color for this region.
In this paper, we decomposed the HSV images using the Discrete Wavelet Transform (DWT) and then quantized the resulted approximation sub band to extract a set of dominant coefficients to form the color vector.
Extracting the color vectors are easy to compute and don’t take long processing time. However, depending on them as a sole factor for deciding the images similarity will usually result it retrieving images with similar color distributions regardless their contents similarity. So extracting texture vectors, which represent the spatial arrangement of pixels in the grey level [9] beside the color ones, becomes an essential step to retrieve more accurate results.
The wavelet-based methods, e.g. standard wavelet t and Gabor wavelet, are the most commonly used techniques to extract the texture vectors as they provide better spatial information [10] [11] . Thirunavuk et al. [12] proposed using the 2D Dual Tree Discrete wavelet transform to each color channel of the YCbCr color space. Then the mean, energy, standard deviation and entropy values were calculated for each of the sub bands. Lahmiri and Boukadoum [13] used the Discrete Wavelet Transform (DWT) to obtain the (HH) frequency sub band and then applied the Gabor filter bank at different scales and orientations. Entropy and uniformity were then calculated and stored; this method gives better and more accurate classification results than using any of the DWT or the Gabor filter alone for extracting the features. In this paper we extracted the texture vectors by converting the images into grey scale ones, after that we applied the DWT and calculated the mean value for each block of pixels for the resulted four frequency sub bands.
The main motivation of this work was to retrieve images that best match the query image in colors and textures. So we suggested clustering the images based on their color vectors to group images with similar color characteristics in the same cluster. The decision on images similarity was made by calculating the Euclidean dis- tance between the query image’s texture vector and the database images’ texture vectors. So the most texturally similar image (I), which is the one that has the minimum Euclidean distance from the query image, was first retrieved and used to identify the index of the cluster within which the search for further similar images was bounded. Results showed that the proposed method allowed retrieving images with better precession average values than others reported in literature [12] [14] .
The rest of this paper is organized as follows: section 2 explains the proposed method, Experimental results and discussions are given in section 3. And section 4 concludes the work.
2. Content-Based Image Retrieval Using Self Organizing Map and Discrete Wavelet Transform
Two kinds of vectors were extracted from each image in the database. The first vector held the color information while the other one was used for the texture information. Images were then clustered according to their color vectors and this process yielded in grouping images with similar color trends in the same and neighboring clusters as we applied the Self Organizing Map (SOM) clustering technique to make use of its topology preserving property [15] . For the query image, we only extracted a texture vector, and then we calculated the texture similarity between it and every single texture vector in the database. The most similar image (I) to the query mage (Q) was first retrieved from the database while other texturally similar images were retrieved from the same cluster of (I). Figure 1 shows the block diagram for the proposed method and the algorithm below concludes the method:
1) Pre-processing: for each image in the database
a) Extract the Color Vector by:
i) Converting the image into the HSV colors space;
ii) Decomposing the image using the DWT for (2) levels;
iii) Quantizing the coefficients the of first color channel of the Approximation (LL2) sub band using SOM;
iv) Taking the most dominant (16) coefficient as color vector;
b) Extract the Texture Vector by:
i) Converting the image into grey scale image;
ii) Decomposing the image using the DWT for (2) levels;
iii) Computing the mean value for each block of pixels for all resulted sub bands.
2) At query time
a) Extract the texture vector in the same way used for the database images;
b) Compare the texture similarity between the query image and the database images;
c) Retrieve the most similar image (I);
d) Define the cluster within which (I) is located;
e) Retrieve other most texturally similar images from the same cluster of (I).
2.1. Extracting Color Vectors
Discrete Wavelet Transformation (DWT) decomposes (analyzes) the image (signal) into a set of approximations and details by passing it through two complementary filters (high pass (H) and low pass (L) filters) [9] (Figure 2). This process results in a sequence of spatially oriented frequency channels called sub bands as follows:
1) The Approximation sub band (LL): describes the low frequency components in the horizontal and vertical directions of the image. It presents the general trend of pixel values (wavelet approximation of the original image);
2) The Horizontal detail sub band (LH): describes the low frequency components in the horizontal direction and the high frequency components in the vertical direction, represents the Horizontal edges;
3) The Vertical detail sub band (HL): describes the high frequency components in the horizontal direction and the low frequency components in the vertical direction, it detects the Vertical edges;
4) The Diagonal detail sub band (HH): describes the high frequency components in both directions, detects the corners.
All of these sub bands can be reassembled back to reproduce the original image without loss of information in a process called reconstruction or synthesis.
DWT is able to decompose the image (R × C) into 4 sub bands with lower spatial resolution (R/2 × C/2) by down sampling it by a factor of (2). However, for each level of decomposition (N) a hierarchal structure of different frequency sub bands (3N + 1) will result, i.e. three levels of decomposition results in (10) different frequency sub bands as shown in figure 3.
We used the HSV color space to extract the color vectors from each image in the database as it was widely used in the previous works [6] [7] and it corresponds closely to the human visual system [16] . A color in the HSV color space is represented by Hue: which is used to distinguish colors and it also represents the nature of the color; Saturation: measures the degree to which a pure color is mixed by white light; and the Value: repre- sents the perceived light intensity [17] . Zhao et al. [18] indicated that the chromaticity component in HSV color pace is separated from the brightness; such that the Value component represents the brightness while Hue and Saturation components represent the chromaticity. To reduce the dimensionality of data and the computation time, we mainly concentrated on the Hue channel as human eye is more sensitive to its variations compared to the variations in Saturation [19] .
We have generated a general approximation for every HSV image by decomposing it for two levels. Decomposing images for more levels will result in more generalization (more down samplings) and more loss of details

Figure 1. Block diagram for CBIR using SOM and DWT.

Figure 2. Discrete wavelet sub-band decomposition.
which will affect the retrieving results. Decomposition process can be concluded by the following two steps:
1) Decompose the image for the first level, this step produces the first (4) sub bands (LL1, LH1, HL1, HH1) and each of which was down sampled by a factor of (2).
2) Decompose the resulted Approximation sub band (LL1) for another level to produce (LL2, LH2, HL2, HH2) and each of which was also down sampled by a factor of (2).
We then quantized the coefficients of the first color channel (Hue) of the (LL2) sub band (as it represents a

Figure 3. Illustrating the 3 levels of decomposition.
general approximation of the image (image icon)) to obtain the most dominant (16) coefficients as discriminating features for the color vector.
We applied the proposed technique on the Wang database after resizing the images to (256 × 256), so the resulted (LL2) sub band had a (64 × 64) size and we found that extracting more than (16) coefficients increased the computation time without adding any significant improvement on the retrieved results.
After extracting the color vectors from the database images, they were clustered in order to group images with similar color characteristics in the same cluster. Quantization and image clustering were both done using the Self Organizing Map (SOM) technique as neural networks algorithms proved many advantageous in vector quantitation [20] and SOM is a well-known unsupervised neural network algorithm which has been used for many applications [21] . Moreover, Pei and Lo [22] indicate that SOM is a good tool for color quantization because of its topology-preserving property, such that it preserves the neighboring pixel relationship [15] and reflects it on the resulted neighboring clusters [23] .
Self Organizing Map (SOM)
SOM is a competitive unsupervised learning clustering technique that is used to classify unlabeled data into a set of clusters displayed usually in a regular Two-Dimensional array [21] . Each cluster in the SOM neural network is referred to as a neuron and associated with parametric reference vector (weight) which has the same dimension as the data to be classified. Self Organizing Map network consists of two layers called the input and the output layers as shown in figure 4.
Each neuron in the input layer is fully connected to every neuron in the output layer using weighted connections (synapses). The output layer structure can have a raw form (One-Dimensional), lattice form (Two-Dimen- sional) or they can be arranged in Three-Dimensional mesh of neurons.
At the beginning a random value is assigned for each of the output neuron (W) vector elements (W = w1, w2, ∙∙∙, wn), these values correspond to the overall density function of the input space and are used to absorb similar input vectors which also have the same dimensionality as the output neurons. Similar input vectors are found according to a predefined similarity measure function, usually the Euclidean distance [23] , according to the following Equation:
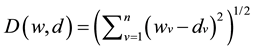 (1)
(1)
D(w, d): Distance function.
wv: the output neuron vector which consists of (n) number of features.
dv: the training input vector which consists of (n) number of features.
In training phase, each training input vector dv (all coefficients of the 1st color channel of the LL2 in the case of color quantization, while the set of all color vectors in the case of image clustering) seeks to find its best similar output neuron Best Matching Unit BMU, which is the one that has the minimum Euclidean distance from

Figure 4. SOM structure.
the currently training input vector, then the weight of the (BMU) and its topological neighbors vectors are stretched toward this training vector according to the following updating rule [21] :
![]() (2)
(2)
e: epoch number as the training phase runs for a specified number of epochs.
wn(e + 1): The weight of neuron ( n) in the next epoch.
wn(e): The weight of neuron ( n) in the current epoch.
α(e): Learning rate at current epoch.
hn(e): The neighbor kernel around the BMU, it defines the region of influence that a training vector has on the SOM.
d(e): The weight of the selected input vector in the current epoch.
By the end of the training phase, the output neurons will have weights that are actually formed by the input space.
In this paper, we used SOM for two purposes: 1) To extract the most dominant coefficients (quantize the coefficients); 2) To group similar images into clusters. In both cases we used the two-dimensional (Grid) output layer structure. However, one input neuron and 16 output neurons were used to extract the most dominant (16) coefficients from the first color channel of the Approximation sub band (LL2). And (16) input neurons (as each color vector has 16 elements) and (9) output neurons were used to cluster images colors vectors for (9) clusters. The number of the extracted coefficients and the number of clusters were experimentally chosen taking into account the computation time.
2.2. Extracting Texture Vectors
To extract the texture vector, all images were converted to grey scale images as [24] defined textures as, “Texture is an attribute representing the spatial arrangement of the grey levels of the pixels in a region or image”, and many researchers extracted texture features from grey scale images as well [25] [26] . Images then were decomposed using the DWT method for two levels and the resulted (4) sub bands (LL2, LH2, HL2, HH2) were used to extract the texture vectors by calculating the mean value for each (8 × 8) block of pixels, the block size was experimentally decided as the size of each of the resulted sub bands was (64 × 64). Extracting the mean value from each (8 × 8) block of pixels will result in a texture vector with 64 elements which will be used then to compare images similarity instead of comparing all (256 × 256) image pixels. The same technique of extracting the texture vector was also applied for the query image (Q).
3. Results
The proposed method has been tested using the Wang database, which has (1000) images in the JPEG format and categorized into (10) categories (African People, Beach, Building, Buses, Dinosaurs, Elephants, Flowers, Horses, Mountains and Food).
First of all, images were resized to (265 × 265) and converted from the RGB color space into the HSV color space. They were down sampled then by decomposing them for two levels using the DWT. As a result, the size of each of the resulted sub bands became (64 × 64).
The first color channel of the LL2 sub band is then quantized using SOM and the most dominant (16) coefficients were selected to form the color vector. After extracting the color vectors, images were clustered into a set of (9) clusters using also the SOM technique, to group images with similar colors characteristics in the same and neighboring clusters.
To extract the texture vectors, all images were converted to grey scale images and also decomposed for two levels using the DWT. The mean value for each (8 × 8) block of the all level (2) sub bands coefficients were computed and stored as texture vectors so each image is stored as vector with (64) elements.
For every query image, the texture vector is extracted by the same way used for extracting the database images texture vectors and the most similar image to the query one is then retrieved by calculating the Euclidean Distance between the query (Q) image texture vector and every texture vector (M) in the database according to the following Equation:
![]() (3)
(3)
where:
D: Distance between the Query image texture vector (Q) and image texture vector (M) in the database.
f : the features index in the texture vector.
The most similar image (the one that has the smallest distance) to the query image is first retrieved while other texturally similar images are retrieved from the same cluster of that image. Each of the images in the database was taken as a query image and compared to the other (999) images while the top (5) similar images were just retrieved. The performance of the retrieval system was measured by calculating the precision value according to the following Equation as it was found in [12] :
![]() (4)
(4)
where:
R: The number of retrieved relevant images.
T: The total number of retrieved images.
Experiments were done by retrieving the most similar images to the query image from the same cluster of the most similar image. Other experiments were also done by retrieving images from neighboring clusters in order to experimentally determine the best retrieval results (figure 5).
Figure 5 shows how the way in which (9) clusters could be arranged in the grid SOM output layer and it also gives an idea about the retrieving process. In (5.A) images were only retrieved from the same cluster (i) of the most similar image, while in (5.B) similar images were retrieved from (5) clusters (cluster (i) and its 4 neighboring clusters). In (5.C) the top (5) similar images were retrieved from (i) and its (8) neighboring clusters.
Figure 6 shows the effect of selecting the top (5) similar images from the same cluster of the most similar image (I) and from its (1, 2, 3, 4, 8) neighboring clusters on the average precision value.
The results showed that retrieving images from the same cluster of the most similar image (I) gives the highest average precision values i.e. the best retrieving results as the retrieving process was focusing on selecting the most texturally similar images from a cluster that bounds images with so much similar colors, unlike retrieving from more than one cluster where the focus was on retrieving the nearest texturally similar images from clusters that have images with different degree of colors similarity.
Selecting from two clusters (the cluster that has the most similar image and one of its four neighbors) gives the lowest precision values as we took the average value for four retrieving experiments i.e. retrieving from one of the 4 neighbors at a time, the same was done for retrieving from 3 and 4 clusters, and this indicates that the location of the neighboring cluster from which the images were selected affect the retrieving results as the num-
![]()
Figure 5. Image retrieving process.
![]()
Figure 6. The effect of retrieving from different number of clusters on average precision value.
ber of similar images that might be grouped in each of the neighboring clusters differs from one cluster to another.
Our results were also compared with others reported in [12] [14] and proved their efficiency over them as depicted in Table 1 and Table 2 shows a sample of visual results.
4. Conclusions
In this article, we proposed a method to retrieve relevant content based images using both color and texture vectors. Images were first clustered based on their most dominant (16) color coefficients, while images texture vectors were extracted by converting them to grey images, decomposing them for two levels using the DWT and calculating the mean value for each block of pixels from the (4) sub bands of level (2).
Results showed that the proposed method is able to retrieve images with higher average precision values than other methods proposed in literature by just comparing the texture similarity and without any need to compare color similarities as images are already grouped according to their colors and the top 5 similar images are retrieved from the same cluster of the image that has most similar texture features to the query image.

Table 1. Average precession values.
Table 2. Visual comparison.
Other techniques may be applied in the future by using stochastic artificial neural network like Restricted Boltzman Machine (RBM) to extract features that might help in matching more accurate results.
References
- Jain, R. and Krishna, K. (2012) An Approach for Color Based Image Retrieval. International Journal of Advanced Electronics and Communication Systems, 2, Paper ID: 10891. http://techniche-edu.in/journals/index.php/ijaecs/article/view/36/29
- Roy, K. and Mukherjee, J. (2013) Image Similarity Measure Using Color Histogram, Color Coherence Vector, and Sobel Method. International Journal of Science and Research (IJSR), 2, 538-543. http://ijsr.net/archive/v2i1/IJSRON2013311.pdf
- Selvarajah, S. and Kodituwakku, S.R. (2011) Analysis and Comparison of Texture Features for Content Based Image Retrieval. International Journal of Latest Trends in Computing, 2, 108-113.
- Kodituwakku, S.R. and Selvarajah, S. (2010) Comparison of Color Features for Image Retrieval. Indian Journal of Computer Science and Engineering, 1, 207-211.
- Mangijao Singha, M. and Hemachandran, K. (2012) Content-Based Image Retrieval Using Color Moment and Gabor Texture Feature. International Journal of Computer Science Issues (IJCSI), 9, 299-309.
- Zhang, L.N., Wang, L.P. and Lin, W.S. (2012) Generalized Biased Discriminant Analysis for Content-Based Image Retrieval. IEEE Transactions on Systems, Man, and Cybernetics Part B, 42, 282-290. http://dx.doi.org/10.1109/TSMCB.2011.2165335
- Stricker, M. and Orengo, M. (1995) Similarity of Color Images Survival Data: An Alternative to Change-Point Models. Proceedings of SPIE Conference on Storage and Retrieval for Image and Video Databases III, Vol. 2420, 381-392.
- Liu, Y., Zhang, D.S. and Lu, G.J. (2008) Region-Based Image Retrieval with High-Level Semantics Using Decision Tree Learning. Pattern Recognition, 41, 2554-2570. http://dx.doi.org/10.1016/j.patcog.2007.12.003
- Singha, M. and Hemachandran, K. (2012) Content Based Image Retrieval Using Color and Texture. Signal and Image Processing: An International Journal (SIPIJ), 3, 39-57.
- Kato, T. (1992) Database Architecture for Content-Based Image Retrieval. Proceedings of the SPIE―The International Society for Optical Engineering, 16, 112-113.
- Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang, Q., Dom, B., Gorkani, M., Hafne, J., Lee, D., Petkovic, D., Steele, D. and Yanker, P. (1995) Query by Image and Video Content: The QBIC System. IEEE Computer, 28, 23-32.
- Thirunavuk, S.K., Ahila, R.P., Arivazhagan, S. and Mahalakshmi, C. (2013) Content Based Image Retrieval Based on Dual Tree Discrete Wavelet Transform. International Journal of Research in Computer and Communication Technology, 2, 473-477.
- Lahmiri, S. and Boukadoum, M. (2013) Hybrid Discrete Wavelet Transform and Gabor Filter Banks Processing for Features Extraction from Biomedical Images. Journal of Medical Engineering, 2013, 1-13. http://dx.doi.org/10.1155/2013/104684
- Bhuravarjula, H.H. and Kumar, V.N.S. (2012) A Novel Content Based Image Retrieval Using Variance Color Moment. International Journal of Computational Engineering Research, 1, 93-99.
- Chang, C.H., Xu, P., Xiao, R. and Srikanthan, T. (2005) New Adaptive Color Quantization Method Based on Self- Organizing Maps. IEEE Transactions on Neural Networks, 16, 237-249. http://dx.doi.org/10.1109/TNN.2004.836543
- Herodotou, N., Palataniotis, K.N. and Venetsanopoulus, A.N. (1999) A Color Segmentation Scheme for Object-Based Video Coding. Proceeding of the IEEE Symposium on Advances in Digital Filtering and Signal Processing, Victoria, 5-6 June 1998, 25-29.
- Rasti, J., Monadjemi, A. and Vafaei, A. (2011) Color Reduction Using a Multi-Stage Kohonen Self-Organizing Map with Redundant Features. Expert Systems with Applications, 38, 13188-13197. http://dx.doi.org/10.1016/j.eswa.2011.04.132
- Zhao, M., Bu, J. and Chen, C. (2002) Robust Background Subtraction in HSV Color Space. Proceedings of SPIE: Multimedia Systems and Applications, Boston, 29-30 July 2002, 325-332.
- Sural, S., Qian, G. and Pramanik, S. (2002) Segmentation and Histogram Generation Using the HSV Color Space for Image Retrieval. Proceedings of IEEE International Conference on Image Processing, 2, 589-592. http://dx.doi.org/10.1109/ICIP.2002.1040019
- Scheunders, P. (1997) A Comparison of Clustering Algorithms Applied to Color Image Quantization. Pattern Recognition Letters, 18, 1379-1384. http://dx.doi.org/10.1016/S0167-8655(97)00116-5
- Kohonen, T. (1990) The Self-Organizing Map. Proceedings of the IEEE, 78, 1464-1480. http://dx.doi.org/10.1109/5.58325
- Pei, S.-C. and Lo, Y.-S. (1998) Color Image Compression and Limited Display Using Self-Organization Kohonen Map. IEEE Transactions on Circuits and Systems for Video Technology, 18, 191-205.
- Kangas, J.A., Kohonen, T. and Laaksonen, J.T. (1990) Variants of Self Organizing Maps. IEEE Trans on Neural Networks, 1,93-99.
- IEEE (1990) IEEE Standard Glossary of Image Processing and Pattern Recognition Terminology. IEEE Standard, 610.4-1990.
- Kavitha, H., Rao, B.P. and Govardhan, A. (2011) Image Retrieval Based on Color and Texture Features of the Image Sub-Blocks. International Journal of Computer Applications, 15, 33-37.
- Moghaddam, H.A., Khajoie, T.T., Rouhi, A.H. and Tarzjan, M.S. (2005) Wavelet Correlogram: A New Approach for Image Indexing and Retrieval. Pattern Recognition, 38, 2506-2518.