Performance Evaluation Approach for Multi-Tier Cloud Applications 79
Run configuration contains specifications of the ramp up,
steady state and ramp down times, the number of users,
output directory, etc. The performance policies include a
series of service level objectives (SLO’s) that define the
performance metrics such as the response time specifica-
tion for each request in the application.
3.6. Deployment Prototyping
Though from the standpoint of a user, the cloud comput-
ing resources should look limit-less, however due to
complex dependencies that exist between servers in va-
rious tiers, applications can experience performance bot-
tlenecks. Deployment prototyping can help in making de-
ployment architecture design choices. By comparing per-
formance of alternative deployment architectures, de-
ployment prototyping can help in choosing the best and
most cost effective deployment architecture that can meet
the application performance requirements.
Given the performance requirements for an application,
the deployment design is an iterative process that in-
volves the following steps:
1) Deployment Design: Create the deployment with
various tiers as specified in the deployment configuration
and deploy the application.
2) Performance Evaluation: Verify whether the appli-
cation meets the performance requirements with the de-
ployment.
3) Deployment Refinement: Deployments are refined
based on the performance evaluations. Various alterna-
tives can exist in this step such as vertical scaling, hori-
zontal scaling, etc.
3.7. Bottleneck Detection
Traditional approaches for bottleneck detection in multi-
tier systems have used average resou rce utilization values
for bottleneck analysis. However, complex-multi-tier
cloud applications can experience non-stationary work-
loads. Average values fail to capture stochastic non-sta-
tionary seasonality in workloads. Therefore, we use ker-
nel density estimates for bottleneck detection. A proba-
bility density esti mate of the data is compu ted based on a
normal kernel function using a window parameter that is
a function of the number of data points. Kernel density
estimates indicate the percentage of time a resource spent
at a particular utilization level. In Section 3.7, we demon-
strate the bottleneck detection approach with three set of
experiments with different deployment architectures.
4. Experiment Setup
To demonstrate the proposed approaches for performance
evaluation, deployment prototyping and bottleneck de-
tection, we used the Rice University Bidding System [13]
benchmark. RUBiS is an auction site prototype which
has been modeled after the internet auction website eBay.
We used a PHP implementation of RUBiS for the ex-
periments. For measuring system statistics, we used sys-
tat and collectd utilities. To study the effect of different
deployment configurations of the application perform-
ance we performed a series of experiments by varying
the architecture model and the application deployment
configurations. The experiments were carried out using
the Amazon Elastic Compute Cloud (Amazon EC2) in-
stances. For the experiments we used small (1 EC2 com-
pute unit), large (4 EC2 compute units) and extralarge (8
EC2 compute unit) instances, where each EC2 compute
unit provides an equivalent CPU capacity of 1.0 - 1.2
GHz 2007 Opteron processor or 2007 Xeon processor.
5. Results
We instrumented the PHP implementation of the RUBiS
benchmark application and obtained the traces of the user
requests. From the analysis of the logged traces the
benchmark and workload models were generated. In the
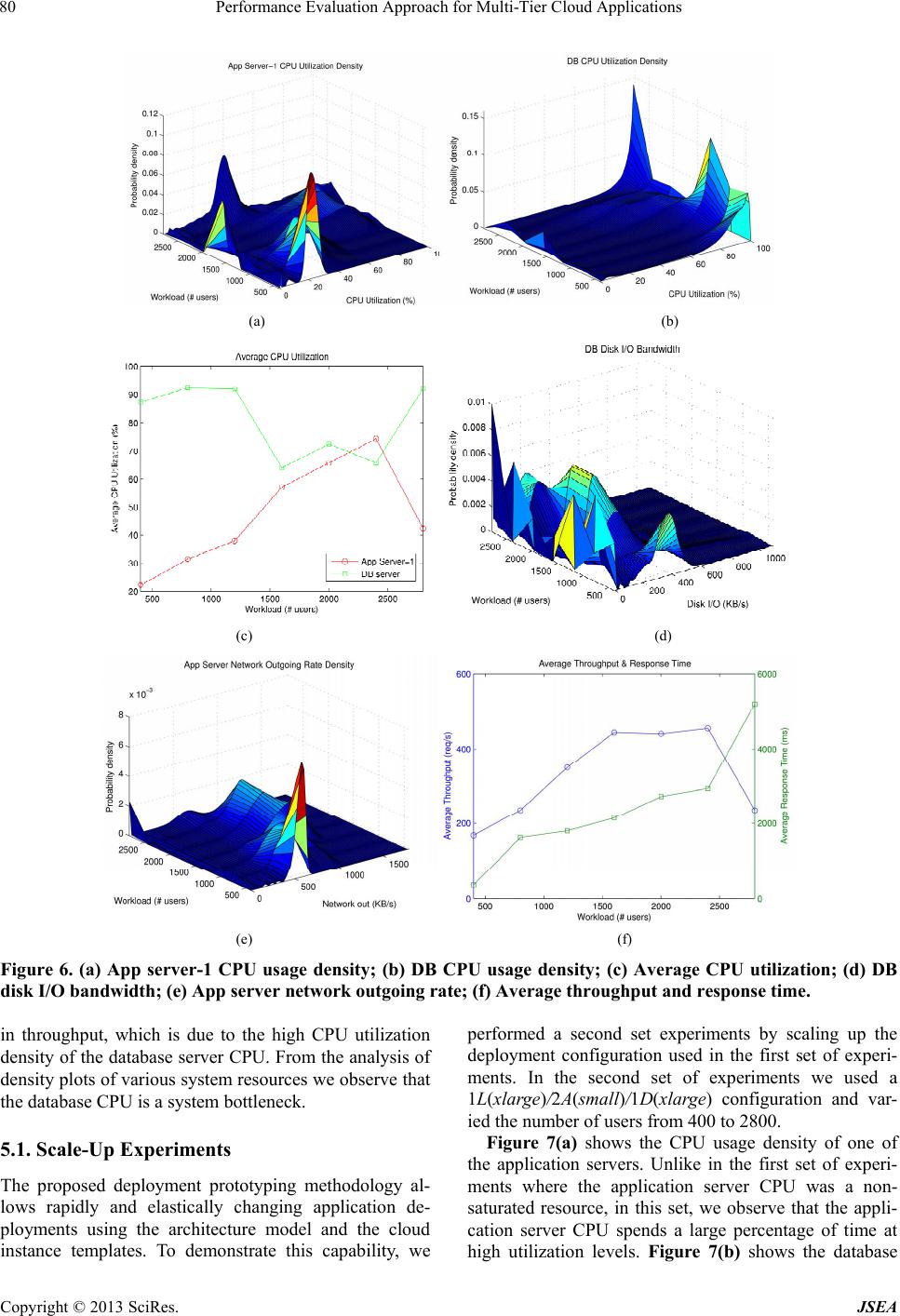
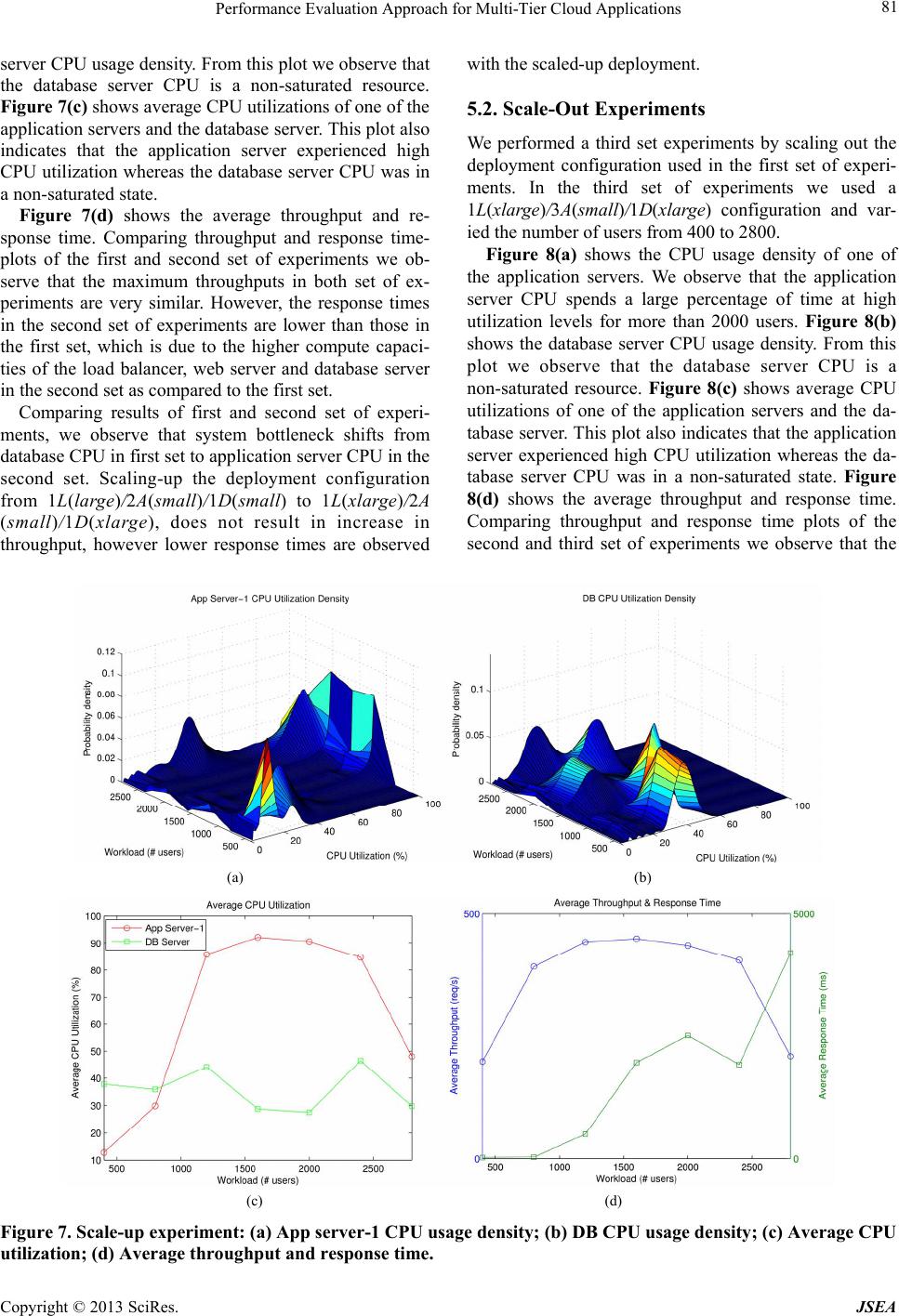
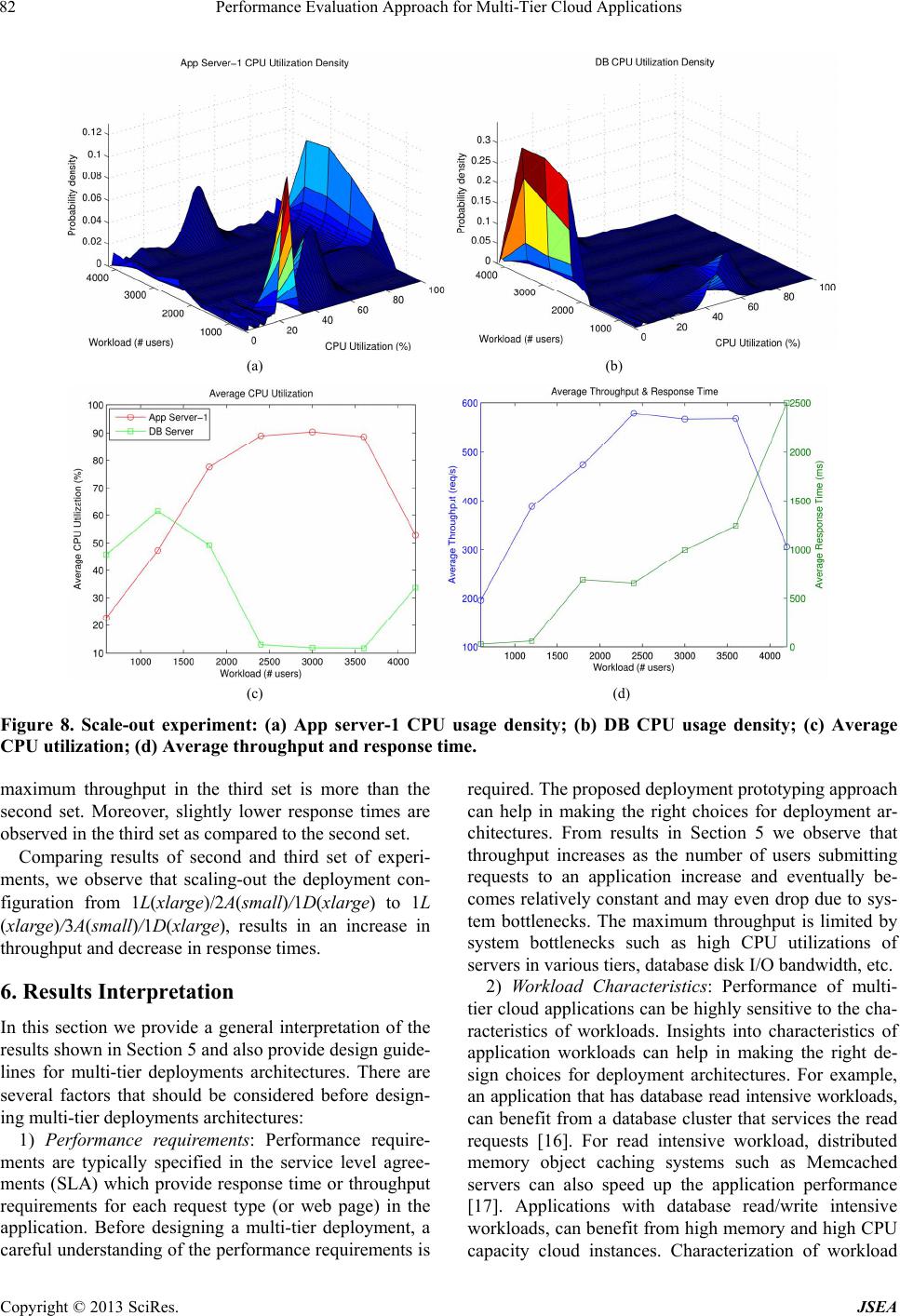
first set of experiments we used a 1L(large)/2A(small)
/1D(small) configuration and varied the number of users
from 400 to 2800. For these experiments we used ramp
up and ramp down times of 1 minute and steady state
time of 10 minutes.
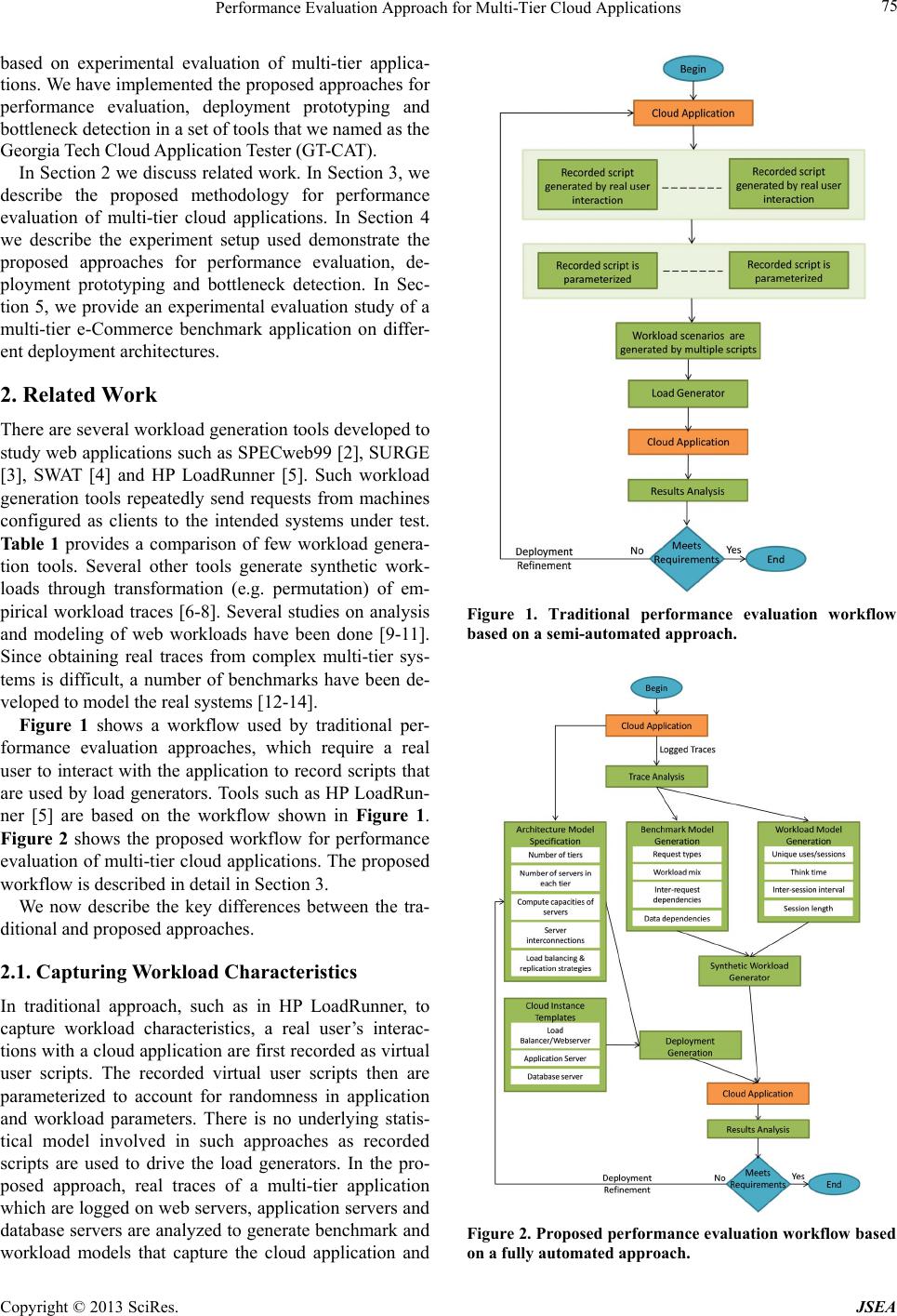
Figure 6(a) shows the CPU usage density of one of
the application servers. This plot shows that the applica-
tion server CPU is non-saturated resource. Figure 6(b)
shows the database server CPU usage density. From this
density plot we observe that the database CPU spends a
large percentage of time at high utilization levels for
more than 2400 users. Figure 6(c) shows average CPU
utilizations of one of the application servers and the da-
tabase server. This plot also indicates that the database
server experienced high CPU utilization whereas the ap-
plication server CPU was is non-saturated state. Figure
6(d) shows the density plot of the database server disk
I/O bandwidth. This plot shows a bimodal shape of the
disk I/O bandwidth density curve. From a thorough
analysis of Figure 6(b), we observe a slight bimodality
in the shape of the database CPU utilization curve for
more than 1500 users. This bimodality in Figures 6(b)
and (d) occurs due to the long read/write requests. When
the database server is servicing a long read/write request,
the CPU utilization remains low while it is waiting for
the I/O.
Figure 6(e) shows the density plot of the network out
rate for one of the app lication servers. Figure 6(f) shows
the average throughput and response time. A strong cor-
relation is observed between the throughput and average
application server network out rate. Throughput con-
tinuously increases as the number of users increase from
400 to 2400. Beyond 2400 users, we observe a decrease
Copyright © 2013 SciRes. JSEA