 Technology and Investment, 2013, 4, 54-66 Published Online February 2013 (http://www.SciRP .org/journal/ti) Copyright © 2013 SciRes. TI Cross-Sectional Estimation Biases in Risk Premia and Ze- ro-Beta Excess Returns Jianhua Yuan, Robert Savickas Yuan is at Capital Market Research Division, Fannie Mae, Washington, DC, USA Savickas is at Department of Finance, George Washington University, Washington, DC, USA Email: jhyuan@gwu.edu and savickas@gwu.edu Received 2012 ABSTRACT This paper shows that the classic cross-sectional asset pricing tests tend to suffer from severe risk-premium estimation errors because of small variation in betas. We explain how the conventional approach uses low criteria to validate an asset -pricing model and suffers from the model-misspecification issue because of the complication associated with the zero-beta excess return. We show that the resulting biases in estimates of risk premia and their standard errors are se- vere enough to lead researchers into inferring incorrect implications about some asset-pricing theories being tested. Further, we suggest that one simple method of mitigating these issues is to restrict the zero-beta excess returns to their theoretical values in the cross-sectional regressions and to conduct the straightforward test of whether the estimated ex-ante risk premia are consistent with the observed ex-post ones. The empirical testing results not only further affirm the higher efficiency of the estimates produces by the suggested method, but also show, contrary to some prior evidence, that the market factor is priced consistently. Keywords: Cross-Sectional Regression; Consistent Estimator; Efficient Estimator; Risk Premium; Zer o-Beta Return; Model Misspecification; Beta-Variation 1. Introduction The two-pass cross-sectional regression (CSR) methodology, which is used in the two classic studies of CAPM---one by Black, Jensen, and Scholes [3, 1972] (BJS) and the other by Fama and MacBeth [12, 1973](FM)---first estimates the factor loadings on the given risk factors in time series regressions and then uses the estimated loadings in the second-pass CSR to estimate the risk premia of the factors. This intuitive two-pass CSR method is easy to implement and has been widely used in the empirical studies of linear beta-pricing models. Despite the wide usage of the two-pass CSR methodology in asset-pricing tests, quite a few issues associated with this classic methodology have been identified in the literature. First, all the three underlying assumptions- -- normality, conditional homoskedasticity, and stationarity---of this two-pass methodology are somewhat disputable. The distributions of most stock returns exhibit significantly positive skewness and higher-tha n -normal kurtosis. Fama [9, 1965] and Blattberg and Gonedes [5, 1974] document the non-normality shown in security returns. The works by Barone-Adesi and Talwar [1, 1983], Bollerslev, Engle, and Wooldridge [6, 1988], and Schwert and Seguin [22, 1990] document the conditional heteroskedasticity of stock returns. For the least worrisome stationarity assumption, Blume [4, 1970] shows that it is not totally inappropriate. The second issue in the asset-pricing tests is the cross-sectional dependence among asset returns. Theoretically, this issue can be handled by a generalized least-square (GLS) estimation but it would be impractical to estimate a huge covariance matrix for a large number of securities. Moreover, such estimated matrix may often not be positive-definite and hence fail the purpose of the GLS methodology. As a more practical approach, the grouping procedure, which was employed in the two classic studies of CAPM---one by BJS and the other by FM, is used to form cross-sectional portfolios. Since the cross-sectional dependence is allowed for grouped data test, the linear beta-pricing models can be tested on returns of the cross-sectional portfolios. As pointed out by BJS, the grouping procedure also allows for any nonstationarity. The third issue associated with the two-pass CSR method is the well-known error-in-variable (EIV) problem. BJS show that the market risk premium estimates will be biased because of the measurement errors in the market beta estimates but argue that the measurement errors can be ignored with large samples of many time periods. FM propose to use lagged rolling beta-estimates to generate a time series of risk premium  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI estimates and then take the mean as the final risk premium estimate. Shanken [23, 1992] provides an excellent discussion of this two-pass CSR methodology, especially the EIV adjustment and the asymptotic distribution analysis under the conditional homoskedastic assumption.1 Kim [15, 1995] provides an EIV correction met ho dology using maximum likelihood estimation. The fourth issue of this classic CSR methodology is related to the common practice of low acceptance criteria for a beta-pricing model. The literature sometimes emphasizes the high cross-sectional and the high t-values of the risk premium estimates (i.e. the estimated risk premium associated with a particular factor is significantly different from zero). Kan and Zhang [14, 1999] conduct simulations in which true asset returns are generated from a one-factor model but the factor in the two-pass CSR tests is misspecified as a random variable uncorrelated with the asset returns. They call such a misspecified factor as a ``useless" factor and show that the t-value of the ``useless" factor converges to a large value in the cross-sectional regression and the probability of a fairly high cross-sectional 2 is quite big. Even though the case they provide is an extreme one and a useless factor may be relatively easy to detect as Jaga nnathan and Wang [13, 1998] have shown, quasi-models whose factors are only weakly correlated with the true factors will be harder to detect. Lewellen, Nagel, and Shanken [16, 2008] (LNS) show that a proposed model with factors only weakly correlated with the true factors and uncorrelated with the errors is capable of producing high cross-sectional . As part of their critique, LNS show that the magnitudes of the zero-beta estimates and the estimated equity risk premium in many papers are unreasonably high and low, respectively. In attempting to improve empirical tests, LNS have offered several prescriptions including GLS estimation, expansion of the set of testing portfolios beyond size-B/M portfolios, imposing related constraints in time-series and/or cross-sectional regressions, and so on. These suggested approaches may improve empirical tests but somehow lose the intuition and the simplicity of the original method. This paper focuses on the fourth issue described above and attributes this problem to the complication of the zero-beta factor. Even though the classic CAPM developed by Sharpe [24, 1964] and Lintner [17, 1965] suggests that the excess return (in excess of risk-free rate) of any asset should be proportional to its market risk loading by the same multiplier (the market risk premium), the early CAPM testing results (e.g. BJS, FM, etc.) show that the estimated CSR intercept tends to be significantly 1Jagannathan and Wang [13, 1998] generalize Shanken's asymptotic analysis to the case of conditional heteroske- dastic returns. positive and the market risk premium seems to be significantly smaller than the ex post equity premium. Possibly motivated by such empirical results, Black [2, 1972] extends the CAPM by including borrowing restriction.2 Black's extended CAPM postulates that the excess return of any asset will be linear in terms of its market beta with the same intercept (the zero-beta excess return) and the same linear coefficient (the market risk premium). The extended Black's CAPM not only is a theoretical extension of the original Sharpe-Lintner CAPM but also seems to reconcile the early CAPM testing results. However, the zero-beta excess returns, which are due to the differences between the costs of (risk-free) borrowing and the returns of risk-free lending, are not observable and are somehow ambiguous. With the complication of the zero-beta excess return, the observed equity premium is no longer an ex-post measure of the ex-ante risk premium and this leads to the common practice of low criteria of model acceptance---high CSR and high -values of risk premium estimates. A more serious problem associated with the conventional cross-sectional regression method is that the estimation errors will be greatly amplified by the small variation among the market betas.3 To address these issues, we advocate focusing on the theoretical linear beta-pricing model that restricts the zero-beta expected return to its theoretical value and testing whether the estimated ex-ante risk premia are consistent with the observed ex-post ones.4 In the theoretical linear beta-pricing model with a risk-free rate, the risk premia are assumed to be observable. In order to find supportive evidence for such a pricing model, one needs to show that the null hypothesis that the estimated (ex-ante) risk premia are equal to the observed (ex-post) ones will fail to be rejected. For a misspecified model, it is unlikely that the estimated risk premium of the misspecified factor can match its observed value. Next, we discuss the importance of this simplification. 5 2Brennan [7, 1971] also provides an excellent analysis on the capital market equilibrium with divergent borrowing and lending rates. 3Notice that the estimation error of the market risk pre- miu m is That is, the testing procedure . 4In our discussion of the two-pass CSR methodologies, we focus on the ordinary least-square (OLS) cross-sectional estimation. But the approach suggested in this paper can be directly applied to the generalized least-square (GLS) cross -sectional estimation, as well. 5Kan and Zhang [14, 1999] show that the risk premium estimate of a useless factor converges to infinity with probability one as . Suppose the factors are stationary and ergodic, then the sample means of the factors will converge to finite numbers and the probabil-  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI for the linear beta-pricing model with a risk-free rate will not suffer from the model-misspecification problem. It has also been proven that the two-pass CSR methodology suffers from the EIV problem and the CSR estimation errors are underestimated. Shanken [23, 1992] shows that it is very important to make the standard error correction in order to find supportive evidence for a linear beta-pricing model with zero-beta excess return, especially one with multiple factors. The estimated risk premia that are significantly different from zero with the uncorrected error estimates may turn into insignificant with respect to the corrected- --and hence larger---error estimates. However, the standard error correction will not be needed if the linear-beta pricing model can be validated with the uncorrected error estimates. That is, if the null hypothesis that the estimated risk premia are equal to the observed ones fails to be rejected with respect to the uncorrected standard errors, it will also fail to be rejected with respect to the corrected (larger) ones. The more important reason that we should focus on the theoretical linear beta-pricing model with risk-free rate is that this method can be applied to obtain more efficient estimates of risk premia. We show that the conventional two-pass estimates from the unrestricted cross-sectional regressions suffer from high estimation errors because of the relatively small variation among betas. Although there are sophisticated, more efficient econometric methods available for evaluating linear beta-pricing models, these methods are generally more complicated and less robust than the two-pass CSR methodology6 One of the prescriptions suggested by Lewellen, Nagel, and Shanken [16, 2008] to improve the efficiency of the WICSR is to impose related constraints in the regressions. According to Shanken [23, 1992], this means to force the risk premium of a portfolio-return factor to be the difference between the mean of the observed factor returns and the average zero-beta excess returns. Hence, for a pricing model with only portfolio-return factors, the cross-sectional estimation reduces to estimating the mean and in some situations, it is difficult to interpret statistical inferences obtained from these methods. As an alternative, the approach of restricted cross-sectional regressions possesses all the advantages---intuitiveness, simplicity, and robustness---of the classic two-pass method while, at the same time, being capable of producing much more efficient estimates than the conventio na l method is. It is also straightforward to interpret the testing results obtained from the method we advocate. ity that the risk premium estimate of a useless factor equals to its ex post risk premium will converge to zero as . 6Cochrane [8, 2001] makes an excellent discussion about tradeoffs between the methods for estimating and eva- luating asset-pricing models. of the zero-beta excess returns. With this restriction, the risk premium of any portfolio-return factor is not directly estimated and the standard error associated with the risk premium of the portfolio-return factor is not estimated. Because of this, it becomes difficult to statistically interpret the estimation results with respect to the portfolio -return factor, especially when the tested model has multiple factors. When focusing on the theoretical linear beta-pricing model with (market equivalent) risk-free rate, we are able to restrict cross-sectional regressions by imposing the zero-intercept constraint, thereby obtaining estimates that are very straightforward to interpret. In the rest of the paper, we proceed as follows. In Section 2, we first describe both the traditional method and the method we advocate. Then we show that both methods are -consistent and derive the asymptotic distributions of the corresponding estimates under the assumptions of conditional heteroskedasticity and/or homoskedasticity. In the last subsection of Section 2, we derive the cross-sectional asymptotic properties and show that the advocated approach is more efficient than the traditional method under the assumption of sufficiently weak cross-sectional dependence. Section 3 presents empirical evidence of the higher efficiency of the methodology we describe. In Subsection 3.1, we provide simulation evidence to illustrate that risk-premium estimates resulting from the restricted cross-sectional regressions are more efficient than the conventional estimates. Subsection 3.2 shows that the warrants for significant zero-beta excess returns are not as strong as believed. In Subsection 3.3, we reexamine the Fama-French three-factor model and provide new cross-sectional supportive evidence. The final section summarizes our findings. 2. The Cross-Sectional Regression Methods for Asset Pricing Tests 2.1. The Mathematical Setup A linear asset pricing model with risk-free rate can be expressed as follows: (1) where is a vector of excess returns (in excess of the risk--free rate) for assets; , the vector of risk premia, is the mean of the asset-pricing risk factors ; and is the matrix of factor loadings of on . Let and denote the covariance matrix between and and the variance-covariance matrix of the factors , respectively. Then (2) An important case of model (1) is the Sharpe-Lintner's CAPM, where is the market excess return and  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI equation (1) is called the Security Market Line. In the general case of Merton's ICAPM, is the vector of excess returns of the market portfolio and the hedging portfolios and equation (1) is called the Security Market Hyperplane. In Ross's APT case, equation (1) will be empirically approximated if returns have a linear factor structure . The classic design of testing the model (1) is to test the following extended linear model: ,=][E λιγ Br + N (3) where scalar is interpreted as the zero-beta excess return; N ι is an -dimensional column vector of ones, and is the column vector of risk premia. Define (4) where N I is the -dimensional identity matrix, then it is easy to see that (5) Henceforth, we drop the subscript N for and for simplicity, as the dimensions of and/or can be implicitly determined. Multiplying equation (3) by , we have (6) Now assume that and that the matrix has full rank , then will also have full rank and ].[E)(=][E)(= 11 rDBDBBrDBDBDB′′′′′′ −− λ (7) Substituting (1) into (7) , we have ].[E=][E)(= 1ffDBBDBB′′ − λ (8) That is, theoretically the basic model (1) can be tested by testing the extended model (3) with the conventional with-intercept cross -sectional regression (WICSR) estimates (7). On the other hand, suppose that has full rank , then by (1) the risk premium can be directly expressed as: (9) And a direct estimation of (9) can be obtained through a no-intercept cross-sectional regression (NICSR). Let and be the matrix of the observed excess returns of the assets and the matrix of the observed values of the factors for the time periods. Assume that and are stationary and the sample moments of and converge to the corresponding unconditional population moments. Then the variance and covariance matrices and can be consistently estimated by , 1 = 1 =FFDFDFD ′′′ Ω (10) and (11) The consistent estimators for and are (12) and 1 1 1 = = () =( ). − − − ΣΩ ′′ ′′ ′′ B RDD FFDD F RDF FDF (13) The classic WICSR estimates for the risk premium and the zero-beta excess return are (14) ). ˆ (' 1 = ˆ λιγ BR − (15) The NICSR estimate for the risk premium is (16) Denote (17) (18) ,= λεεε B R−(19) then we can obtain estimation errors of the WICSR risk premium estimate by equations (7) and (14) (20) Similarly, equations (9) and (16) give the errors of the NICSR risk premium estimate .)(= ~1 ελλ 'BB'B − −(21) 2.2. Asymptotic Distributions of the Estimators In the previous subsection, we have laid out the mathematical definitions of both the WICSR and NICSR estimators. Next we present the asymptotic distribution properties of the risk premium estimator given by the  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI conventional WICSR in (14) and that produced by NICSR in (16). The assumption of conditional heteroskedasticity we make here is similar to the one made by Jagannathan and Wang [13, 1998]. Proposition I: Assume that 1) the time series of returns and factors are stationary and ergodic, 2) as , the random vector converges to a zero-mean random vector with covariance matrix , and 3) both and have full rank of , then in (20) converges in distribution to a zero-mean random vector with covariance matrix ;)()(= 11 −− ′ Ψ ′′DBBDBDBDBBV (22) in (21) converges in distribution to a zero-mean random vector with covariance matrix .)()(= 11 −−′ Ψ ′′ BBBBBBV (23) Proof: Since the time series of returns and factors are stationary and ergodic, , and will converge in probability to , and , respectively. Hence (22) and (23) immediately follow from the assumption that the random vector converges to a zero-mean random vector with covariance matrix .7 Q.E.D. Since the true risk premium is not observable, the CSR risk premium estimate can only be tested against the sample mean of the observed risk premium: (24) In order to test the basic model (1), the classic WICSR methodology tries to test the following null hypotheses8 1 0:H : Sufficiently high to show that the variation in cross-sectional average excess returns can be explained by the variation in the factor loadings ; 7These two results can be derived as special cases of Ja- gannathan and Wang's [13, 1998] Theorem 1. 8To fully validate an asset pricing model, it is very essen- tial to test the hypothesis that all pricing errors are jointly zero. Since the focus of this paper is on the risk premium estimation but not on the validation of any specific model, we only perform tests associated with risk premium es- timates. • ; • . Using the NICSR approach, we would like to test the next two null hypotheses: • Sufficiently high to show that the levels of the cross-sectional average excess returns can be explained by the levels of the factor loadings ; • . For these purposes, the empirical time-series form of (1) is introduced as follows: (25) where is the matrix of idiosyncratic errors with and . And the empirical cross-sectional form of (1) is ,= e+FBR (26) where . By equations (13) and (25), we get (27) After rewriting equation (26) in terms of , we have .= εε +≡−+FBFFBR B e(28) Using equation (28), we obtain the conditional errors of the CSR risk premium estimators given the factor realization : (29) f (30) Similar to the previous results on the asymptotic distribution of the unconditional error of the risk premium estimators, the asymptotic distribution properties of errors of the risk premium estimators conditioning on the realization of the risk factors in (29) and (30) can be given as follows. Proposition II:9 Assume that 1) the time series of returns and factors are stationary and ergodic, 9Shanken [23, 1992] presents a comprehensive asymp- totic analysis for the conditional error distribution of the  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI 2) as , the random vector converges to a zero-mean random vector with covariance matrix , and 3) both and have full rank of , then in (29) converges in distribution to a zero-mean random vector with covariance matrix ;)()(= 11 −− ′ Π ′′DBBDBDBDBBW (31) in (30) converges in distribution to a zero-mean random vector with covariance matrix .)()(= 11 −− ′ Π ′′ BBBBBBW (32) Proof: Similar to the proof of Proposition I. Q.E.D. In order to conduct the statistical tests on the hypotheses , , , 1 0 H , and 2 0 H , researchers typically make the assumption that the idiosyncratic errors are conditionally homoskedastic on the realization of the risk factors with constant covariance matrix . Under this conditional homoskedastic assumption, we obtain the following result. Proposition III:10 Assume that 1) the time series of returns and are stationary and ergodic and 2) the idiosyncratic errors are independently, identically distributed with mean 0 and covariance matrix conditional on the realization of the risk factor , then .)'(1= 1ΦΩ+Π − λλ (33) It is well known that the two-pass cross-sectional method suffers from the EIV problem. From (28) we see that the conditional errors have two components: and . Proposition III indicates that under the conditional homoskedasticity, these two error components will be conditionally independent with asymptomatic covariance matrices and ΦΩ− λλ 1 ', respectively. To account for the estimation errors in betas, Shanken [23, 1992] suggests to adjust the standard errors according to (33). That is, the estimated errors should be inflated by and by for the conventional with-intercept cross-sectional estimates under the stronger assumption that the idiosyncratic er- rors are homoskedastic. 10We omit its proof here and readers can refer to Theo- rem 1 of Shanken [23, 1992], as it directly follows. conventional WICSR estimates and the NICSR ones, respectively. 2.3. Cross-Sectional Asymptotic Properties The asymptotic distribution analyses in Subsection 2.2 show that the estimators of both the classic WICSR and the NICSR are -consistent. This indicates that the two-pass estimation leaves little to be desired with regard to its large-sample properties as . In this subsection, we examine the cross-sectional asymptotic properties of these two CSR estimators and show that the NICSR method is likely more efficient than the conventional WICSR method, provided that is large enough and the cross-sectional dependence of idiosyncratic errors is weak enough. It is known that the traditional WICSR estimator is not -consistent. That is, the risk premium estimate will not converge in probability to the average observed realizations as . One obvious reason for this is the EIV issue, and the other more fundamental problem is that the true risk loadings and the cross-sectional average of the idiosyncratic errors may be correlated.11 The NICSR estimator is certainly not -consistent, either. But under the general assumption of sufficiently weak cross-sectional dependence of idiosyncratic errors, the cross-sectional average of the idiosyncratic errors in (28) tends to cancel away and the advocated NICSR method will be more efficient than the classic WICSR approach. There are two empirical evidences for our claim. First, Miller and Scholes [20, 1972] have documented that high-beta assets tend to have negative alphas and that low-beta stocks tend to have positive alphas12 . This indicates that when is large enough, the cross-sectional average of the estimated alphas will be quite small as negative alphas of the high-beta stocks and the positive alphas of the low-beta assets will cancel each other. Notice that the conditional estimation errors in equation (28) will be the estimated alphas in the CAPM case. This implies that 11Most researchers simply assume that the cross-sectional error is uncorrelated with the true risk loading . Empirically, we see that the correlation between β and is quite large compared with the beta-variation. 12Even though the measurement error will contribute to the negative correlation between and , the measurement error in is minimal for CAPM and the significant cross-sectional correlation is between al- phas and true betas.  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI BBBBDBDBDBDBΠ≈ ′′ Π ′'=''= εεεε . Secondly, Black, Jensen, and Scholes [3, 1972] report that the market betas tend to be concentrated near the value of one with relatively small variation and one of the purposes of their grouping procedure is to obtain maximum possible dispersion among betas. This implies that the square matrix is likely significantly more positive definite than the square matrix . Combining these two points, we know that the positive definite matrix in (31) should have bigger norm than in (32). To formalize this empirical argument, we produce the following result. Theorem I: Assume that 1) the idiosyncratic errors have mean 0 and sufficiently weak cross-sectional dependence; and 2) as , , B'B 1, and ε D'B 1, converge to ] [E β , , and , respectively, then • as , ; • as , the estimation error of the conventional WICSR risk premium estimate converges to );, ˆ (cov) ˆ (var ˆ 1 εββλ − →− F (34) • as , the estimation error of the NICSR risk premium estimate converges to 1 ˆ (var( ) ˆˆˆ E[]E[])cov(,). λβ β ββε − −→ ′ + F (35) Proof: Suppose that the time-series variances of the idiosyncratic errors are bounded, then by the weak law of large numbers e ι ′ 1 converges in probability to vector . Hence by (27) and (28), (i) directly follows. (ii) is the immediate result of assumption 2) and equation (29). Notice that and from Equation (30), we have that (iii) directly follows the above results (i) and (ii). Q.E.D. The two conditions in Theorem I are typically assumed in the analysis of -consistency of the two-pass CSR method. If we further assume that the true risk loading betas are uncorrelated with the idiosyncratic errors , then (34) becomes 1 1 ˆˆˆ ˆˆ var ()cov(,) =[var()var( )][var( )cov(,)].e ββ β β βε βε εε − − ++F (36) The asymptotic result (36) is basically the one reported by Black, Jensen, and Scholes [3, 1972]. Under the further assumption of conditional homoskedasticity, they argue that errors and can be ignored for large and hence the CSR estimator is -consistent. Shanken [23, 1992] formally proves that the ``OLS version" of maximum likelihood estimation of the zero-beta excess return is -consistent under the assumptions that the idiosyncratic errors are homoskedastic and cross-sectionally uncorrelated with the true betas. The asymptotic result (34) in Theorem I indicates that three factors---beta variation, EIV, and the average idiosyncratic error over time--- will determine the estimation error of the CSR risk premium estimate. The existing literature emphasizes EIV correction but pays little attention to the impact of beta variation. BJS point out that one of the purposes of the grouping procedure should be to maximize the variation among betas. But this seems to be difficult in portfolio grouping. Kim [15, 1995] even suspects that the formation of portfolios for the CSR estimation might cause a loss of valuable information about cross-sectional behavior among individual assets. And one of the prescriptions suggested by LNS to improve empirical tests is to expand the set of test portfolios beyond the size-B/M portfolios. The expansion of the set of test portfolios tends to increase the variation among betas and hence can improve the CSR estimations. As the asymptotic property (35) indicates, our preferred NICSR methodology will barely suffer from the small beta-variation as the total square sum of betas is used. Hence the NICSR approach will be more efficient than the traditional WICSR method. 3. Empirical Results In the previous section, we have shown that the NICSR method will be more efficient than the classic WICSR approach in the tests of the linear beta-pricing models. In this section, we present our supporting empirical evidence. First, we employ simulations to show this point. Then, we test the CAPM with the actual stock returns for the early subsample. In the last subsection, we reexamine the Fama-French three-factor model. 3.1. CAPM Simulations  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI In this subsection, we employ simulations to demonstrate that the NICSR approach will be more efficient than the WICSR method in tests of the linear beta-pricing models. There are twenty-five series of simulated excess return data generated according to the CAPM ,= itMtiit e+RR β (37) where the market excess returns are the actual Fama-French market factor monthly time series between July 1926 and June 2007 and the market risk loadings are the actual estimated market betas of the 25 Fama-French size-B/M cross-sectional portfolios for the same period13 . The simulated idiosyncratic errors in (37) are cross-sectionally independent and are independently, identically, normally distributed with mean zero and variance across time, where are the variances of the 960-period idiosyncratic residuals of the 25 value-weighted Fama-French size-B/M portfolios regressed on the Fama-French market factor.14 With the 25 simulated cross-sectional excess returns, we first perform the usual pass-one time-series regression on the given fixed Fama-French market factor to estimate betas and then run both the classic WICSR test and the NICSR one with the cross-sectional average excess returns. The simulations and the regressions are repeated 100 times. Figures 1 and 2 graphically show the actual errors and Figure 1: Actual Errors in Risk Premium Estimates. the estimated standard errors of the risk premium estimates of the 100 simulations, respectively. We clearly see that the errors in the risk premium estimates for the WICSRs are in general much larger than those for the NICSRs. In Table 1, we list some summary 13Twelve data points with missing data between July 1930 and June 1931 are excluded. 14For simplicity, the idiosyncratic errors are assumed to be cross-sectionally independent. This simplification is not too restrictive as the NICSR method can be directly generalized to the GLS case. Figure 2. Estimated Standard Errors of Risk Pre- mium Estimates statistics---means, standard deviations, minima, and ma xima---of the errors in the risk premium estimates of the 100 simulations for both the methods. These specific statistics again show that the NICSR approach is more efficient than the WICSR method. Table 2 shows the number of rejections of the true hypotheses or the Sharp e -Lintner CAPM model for both methods. The lower frequency of the false rejections for the NICSR method also indicates that the NICSR method is more efficient and more robust than the WICSR approach. Table 1. Statistics of Errors in RP Estimates Dev. Panel A: CSR Tests Using Estimated betas Panel B: CSR Tests Using Actual betas In Section 2, we show that the NICSR method tends to be more efficient because the risk loading betas cross-sectionally center around one with small variation, and the time-series average idiosyncratic errors diversify away considerably when they are averaged in the CSR. The cross-sectional average and the variance of the market betas of the Fama-French twenty-five cross-sectional portfolios are 1.225 and 0.030, respectively. Hence by Theorem I, the errors in risk premium estimates generated by the WICSRs can be up to roughly fifty-one15 15 times as large as those by the NICSRs. The simulation results reveal that, on average, this ratio is about ten. Proposition III specifies the asymptotic standard EIV adjustment. For our simulations here, the mean and the variance of excess returns of the Fama-French market portfolio are 0.688 and 28.714, respectively, and hence  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI Table 2: Number of Rejections of the CAPM cal Values Panel A: CSR Tests Using Estimated betas Panel B: CSR Tests Using Actual betas the corresponding asymptotic standard error adjustment will be only 0.016. Panel B of Table 1 and Panel B of Table 2 show the summary statistics of the errors in the risk premium estimates and the numbers of false rejections of CAPM, respectively, among the 100 simulations when the actual betas are used. Obviously the EIV issue here is statistically insignificant and this is consistent with the findings of Black, Jensen, and Scholes [3, 1972] and Shanken [23, 1992]. And this fact shows that the relatively large errors of the risk premium estimates in WICSRs (compared with those in NICSRs) can not be significantly reduced by the maximum likelihood estimations that try to eliminate the errors in variables. Even though a very low CSR may indicate that the hypothetical asset-pricing model should be rejected by the data, 2 by itself can not be the appropriate measure of the model fit. Recently, Lewellen, Nagel, and Shanken [16, 2008] have shown that proposed asset -pricing factors that are even weakly correlated with the true factors and uncorrelated with the errors are capable of producing high cross-sectional and one of their recommendations is to take the magnitude of estimates more seriously. Our simulation results reaffirm their point. As shown by the scatter-plot in Figure 3, high can be associated with estimates with large errors, and low 2 may correspond to relatively good estimates. Figure 3. Scatter Plot (P-Value vs ) 3.2. CAPM Tests with Returns in the Early Subperiod In Section 2 we have proven that the NICSR estimation is more efficient than the classic WICSR estimation. We have also described some supportive simulation evidence in the previous subsection. However, we should be aware that NICSR estimation is not appropriate for the extend ed model (3). In the empirical asset-pricing literature, the extended form (3) is typically directly assumed even though the theoretical models generally assume the existence of risk-free rate and are all in the basic form (1). The immediate reason of this practice may be the extensively common usage of the ordinary with-intercept linear regressions and the relatively rare application of the no-intercept linear regressions. But the main reason of this practice should be the rejection of the original Sharpe-Lintner CAPM and the endorsement of the extended Black CAPM by the early classic CAPM testing works of Black, Jensen, and Scholes [3, 1972] and Fama and MacBeth [12, 1973]. In this subsection, we show that the evidence and warrants for rejection of the basic model (1) are not as strong as believed. As Lewellen, Nagel, and Shanken [16, 2008] point out, the magnitudes of the estimated zero-beta excess returns are unreasonably high in many of the existing empirical results. According to the theoretical explanation16 of the zero-beta excess return, it is a weighted average of the differences between the costs of risk-free borrowing and the returns of risk-free lending and hence should be within the approximate range17 between 0 and 0.2% per month. Black, Jensen, and Scholes [3, 1972] report the estimates of the zero-beta excess returns to be 0.338%, 0.849%, 0.420%, 0.782%, and 0.997% for the periods 1/31-12/65, 1/31-9/39, 10/39-6/48, 7/48-3/57, and 4/57-12/65. These estimates (4.056%, 10.188%, 5.04%, 9.384%, and 11.964% if annualized) are just too big to be due to the rate differences between (risk-free) borrowing and risk-free lending and the huge negative estimate of 0.849% for period 1/31-9/39 is even more spurious if it is interpreted by the borrowing restriction argument. The analyses in Section 2 and the above simulations in Subsection 3.1 suggest that at least one cause of the unreasonable magnitudes of the risk premium estimates and the zero-beta excess return estimates are the likely large errors of the WICSR estimates. In the rest of this subsection, we illustrate this point with our empirical 16Brennan [7, 1971] refers to the zero-beta rate as the market's equivalent risk-free rate and shows that it is a weighted average of the risk-free borrowing rate and the risk-free lending rate. 17Lewellen, Nagel, and Shanken [16, 2008] give their estimates of zero-beta excess returns to be between 0 and 2% per year. 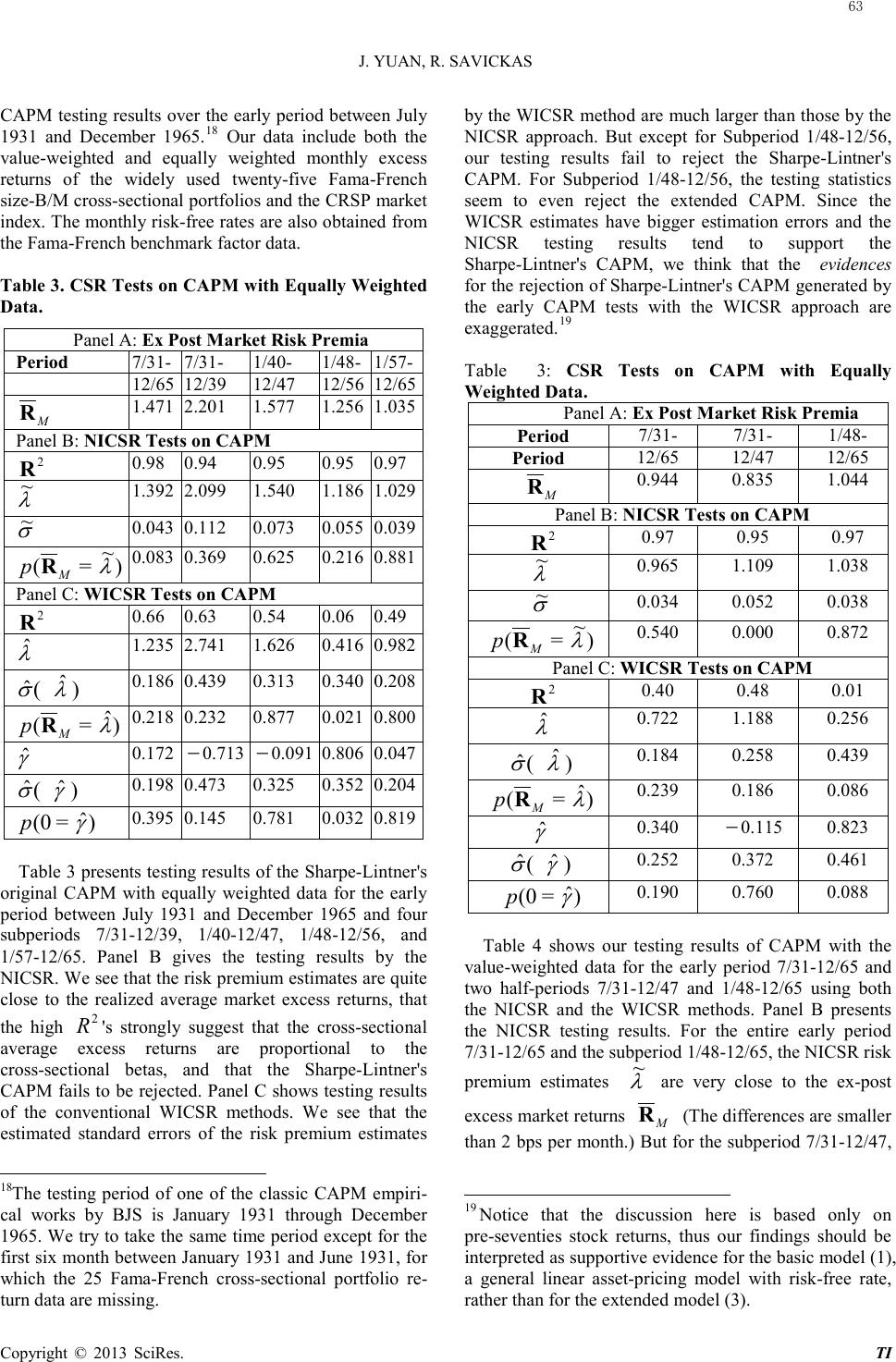 J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI CAPM testing results over the early period between July 1931 and December 1965.18 Panel A: Ex Post Market Risk Premia Our data include both the value -weighted and equally weighted monthly excess returns of the widely used twenty-five Fama-French size-B/M cross-sectional portfolios and the CRSP market index. The monthly risk-free rates are also obtained from the Fama-French benchmark factor data. Table 3. CSR Tests on CAPM with Equally Weighted Data. M R Panel B: NICSR Tests on CAPM Panel C: WICSR Tests on CAPM λ ) =( λ M pR ) ( γσ Table 3 presents testing results of the Sharpe-Lintner's original CAPM with equally weighted data for the early period between July 1931 and December 1965 and four subperiods 7/31-12/39, 1/40-12/47, 1/48-12/56, and 1/57-12/65. Panel B gives the testing results by the NICSR. We see that the risk premium estimates are quite close to the realized average market excess returns, that the high 's strongly suggest that the cross-sectional average excess returns are proportional to the cross-sectional betas, and that the Sharpe-Lintner's CAPM fails to be rejected. Panel C shows testing results of the conventional WICSR methods. We see that the estimated standard errors of the risk premium estimates 18The testing period of one of the classic CAPM empiri- cal works by BJS is January 1931 through December 1965. We try to take the same time period except for the first six month between January 1931 and June 1931, for which the 25 Fama-French cross-sectional portfolio re- turn data are missing. by the WICSR method are much larger than those by the NICSR approach. But except for Subperiod 1/48-12/56, our testing results fail to reject the Sharpe-Lintner's CAPM. For Subperiod 1/48-12/56, the testing statistics seem to even reject the extended CAPM. Since the WICSR estimates have bigger estimation errors and the NICSR testing results tend to support the Sharp e -Lintner's CAPM, we think that the evidences for the rejection of Sharpe-Lintner's CAPM generated by the early CAPM tests with the WICSR approach are exaggerated.19 Panel A: Ex Post Market Risk Premia Table 3: CSR Tests on CAPM with Equally Weighted Data. M R Panel B: NICSR Tests on CAPM Panel C: WICSR Tests on CAPM Table 4 shows our testing results of CAPM with the value -weighted data for the early period 7/31-12/65 and two half-periods 7/31-12/47 and 1/48-12/65 using both the NICSR and the WICSR methods. Panel B presents the NICSR testing results. For the entire early period 7/31-12/65 and the subperiod 1/48-12/65, the NICSR risk premium estimates are very close to the ex-post excess market returns M R (The differences are smaller than 2 bps per month.) But for the subperiod 7/31-12/47, 19 Notice that the discussion here is based only on pre-seventies stock returns, thus our findings should be interpreted as supportive evidence for the basic model (1), a general linear asset-pricing model with risk-free rate, rather than for the extended model (3).  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI is considerably larger than M R. This evidence seems to imply the rejection of the Sharpe-Lintner CAPM. However, we feel that the estimated risk premium for the subperiod 7/31-12/47 is reasonable because the subperiod 7/31-12/47 spans over the time of the Great Depression and the World War II.20 3.3. Multifactor Asset-Pricing Tests In the above subsection, we have presented empirical evidence to show that the NICSR method is more efficient than the WICSR for CAPM testing. In this subsection, we show the higher efficiency of the NICSR method when testing the Fama-French three-factor model. Fama and French ([10, 1993] and [11, 1996]) propose a three -factor model that explains more than 90% of the time-series variation in portfolio returns and more than 75% of the cross-sectional variation in their average returns. But the traditional WICSR estimates of the market risk premium are not significant at all and the estimated zero-beta excess returns are unreasonably high. It is obviously contradicting that the market factor has strong explanatory power in the time series but little explanatory capability in the cross-section of stock returns. Panel C shows the corresponding WICSR testing results and again the estimated standard errors of WICSR are significantly larger than those of NICSR. The two null hypotheses fail to be rejected in all the four testing periods. However, one can hardly be convinced that the CAPM holds by these results as the errors are so big and the estimated risk premium is essentially indifferent from 0 for the subperiod 1/48-12 /65. Kim [15, 1995] shows that the WICSR market risk premium estimates with size factor present can still be significant when the errors-in-variables are corrected and the number of portfolios is large enough (say larger than 400). As we show in Section 2, small variation among cross-sectional betas amplifies estimation errors, and the EIV introduces systematic bias. The empirical results reported by Kim will be more accurate than the traditional WICSR testing results since expansion of the set of test portfolios tends to enlarge the beta-variatio n-- -this is also one of the prescriptions suggested by Lewellen, Nagel, and Shanken [16, 2008]. In this subsection, we present our NICSR empirical testing results on the Fama-French three-factor model, which not only show that the market risk premium is cross-sectionally significant but also provide new 20Cochrane [8, 2001] suggests to make the standard error correction to account for the error of the sample mean of the market factor. Here the standard error correction will increase the uncorrected standard error by more than 0.5% per month and the null hypothesis will be fail to be rejected. cross-sectional supportive evidence for the Fama-French three -factor model. The data consist of monthly value-weighted returns of the 25 Fama-French size-B/M cross-sectional portfolios and monthly data of the three Fama-French benchmark factors, namely the market excess returns and the returns of the two mimicking portfolios of SMB (smal l-mi nus-big) and HML (high-minus-low), for the time period between July 1926 and June 2007. Twelve data points between July 1930 and June 1931 are excluded because of missing data in the 25 Fama-French size-B/M cross-sectional portfolio returns. The CSR estimation for the Fama-French three-factor model is performed for the specified whole period and four subperiods, 7/26-6/47, 7/47-6/67, 7/67-6/87, and 7/87-6/07. Table 5 shows the CSR testing results on the Fama-French three-factor model. Panel A lists the realized average values of the three Fama-French factors. In Panel B, we see that the market risk premium estimates are not only significant but also are statistically indifferent from the realized ex-post market risk premium. The estimated risk premia of the size factor and the B/M factor are also found to be statistically indifferent from the realized average factor values. As shown in Panel C, the conventional WICSR estimates are spurious with the negative market risk premium estimates and the unreasonably high estimated zero-beta excess returns. Overall, we see that the NICSR method generates more efficient risk premium estimates (in terms of smaller estimated standard errors) for the market factor than the WICSR method and comparable estimates of the risk premia and the standard errors for the SMB and the HML factors to those generated the by the WICSR method. 4. Conclusions This paper shows that the classic cross-sectional regression approach to asset pricing tests tends to suffer from severe estimation errors because of the small beta-variation. We argue that it uses low criteria to validate an asset-pricing model and suffers from the model-misspecification issue because of the complication of the zero-beta excess return. To address this problem, we advocate focusing on the theoretic linear beta-pricing model that assumes a (market equivalent) risk-free rate and directly testing whether the ex-ante risk premium estimates are consistent with the observed ex-post risk premia, which allows one to easily detect misspecified models. Under the assumption that asset returns follow a stationary and ergodic process, we derive the asymptotic distribution of the estimators of the method we advocate. We also show that this approach will be more efficient than the conventional method, provided that the  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI idiosyncratic errors have sufficiently weak cross- sectional dependence.21 Panel A: Realized Averages of the FF Factors Table 5. CSR Tests on FF Three-Factor Model. SMB R Panel B: NICSR Tests on FF Three-Factor Model SMB Panel C: WICSR Tests on FF Three-Factor Model 2 2 3 9 7 21The assumption of weak cross-sectional dependence is also made by Black, Jensen, and Scholes [3, 1972], and by Shanken [23, 1992] in their -cons i stency analyses for the cross-sectional regression methods. Based on our strong evidence of higher efficiency of the NICSR ap- proach, this assumption should also be quite reasonable. SMB Our simulation results provide further empirical evidence of higher efficiency of the approach we describe and show that the relatively large estimation errors of the conventional estimates are not due to the error-in-variable issues. The simulations also indicate that the cross-sectional alone is an inappropriate criterion of the model fit even if the correct factors are used. We reexamine the original Sharpe-Lintner CAPM with monthly stock returns for the early period between July 1931 and December 1965. Testing results of CAPM with the actual stock return data for the early subperiod further affirm that the estimates of the market risk premium generated by the approach advocated in this paper are more efficient than those by the classic method and show that the warrants of the significant zero-beta excess return are not as strong as believed. We also reexamine the Fama-French three-factor model. It is well known that the market beta loses explanatory power on the cross-sectional average returns when the size factor is included as an additional explanatory variable. With the five conventional estimations (one for the whole period and four for four subperiods), the estimated zero-beta excess returns are unreasonably high and the market risk premium estimates are all negative. But with all the five estimations using the suggested approach, not only are all the market risk premium estimates significant, but also all the three risk premium estimates are statistically indifferent from the realized average prices of the three risk factors. Furthermore, the standard error estimates for the market factor given by this method are much smaller than those by the conventional method. These findings illustrate the spurious nature of the conventional estimates and show that the market factor is consistently  J. YUAN, R. SAVICKAS Copyright © 2013 SciRes. TI priced in the Fama-French three-factor model. REFERENCES [1] Barone-Adesi, G. and P. Talwar (1983), ``Market Models and Heteroskedasticity of Security Returns,'' Journal of Business and Economic Statistics 1, 163--168. [2] Black, F. (1972), ``Capital Market Equilibrium with Re- stricted Borrowing,'' Journal of Business 45, 444--455. [3] Black, F., M. Jensen, and M. Scholes (1972), ``The Capi- tal Asset Pricing Model: Some Empirical Tests,'' Studies in the Theory of Capital Markets Praeger, New York, NY, 79--121. [4] Blume, M. (1970), ``Portfolio Theory: A Step toward Its Practical Application,'' Journal of Business 45, 444-455. [5] Blattberg, R. and N. Gonedes (1974), ``A Comparison of the Stable and Student Distributions as Statistical Models of Stock Prices,'' Journal of Business 47, 244--280. [6] Bollerslev, T., R. Engle, and J. Wooldridge (1988), ``A Capital Asset Pricing Model with Time Varying Cova- riances,'' Journal of Political Economy 96, 116--131. [7] Brennan, M. J. (1971), ``Capital Market Equilibrium with Divergent Borrowing and Lending Rates,'' Journal of Fi- nancial and Quantitative Analysis 6(5), 1197--1205. [8] Cochrane, J. H. (2005), Asset Pricing, Princeton Univer- sity Press, Second Edition. [9] Fama, E. (1965), ``The Behavior of Stock Market Prices,'' Journal of Business 38, 34--105. [10] Fama, E. and K. French (1993), ``Common Risk Factors in the Returns on Stocks and Bonds,'' Journal of Finan- cial Economics 33(1), 3--56. [11] Fama, E. and K. French (1996), ``Multifactor Explana- tions of Asset Pricing Anomalies,'' Journal of Finance 50(1), 131--155. [12] Fama, E. and J. MacBeth (1973), ``Risk, Return, and Equilibrium: Empirical Tests,'' Journal of Political Economy 71, 607--636. [13] Jagannathan, R. and Z. Wang (1998), ``An Asymptotic Theory for Estimating Beta-Pricing Models Using Cross-Sectional Regression,'' Journal of Finance 53(4), 1285--1309. [14] Kan, R. and C. Zhang (1999), ``Two-Pass Tests of Asset Pricing Models with Useless Factors,'' Journal of Finance 54(1), 203--235. [15] Kim, D. (1995), ``The Errors in the Variables Problem in the Cross-Section of Expected Stock Returns,'' Journal of Finance 50(5), 1605--1634. [16] Lewellen, J., S. Nagel, and J. Shanken (2008), ``A Skep- tical Appraisal of Asset-Pricing Tests,'' Journal of Finan- cial Economics 96(2), 175--194. [17] Lintner, J. (1965), ``The Valuation of Risk Assets and the Selection of Risky Investments in Stock Portfolios and Capital Budgets,'' Review of Economics and Statistics 47, 13--37. [18] Merton, R. C. (1973), ``An Intertemporal Capital Asset Pricing Model,'' Econom etrica 41, 867--887. [19] Merton, R. C. (1992), Continuous-Time Finance, Black- well Publishing, Revised Edition. [20] Miller, M. H. and M. Scholes (1972), ``Rates of Return in Relation to Risk: A Reexamination of Some Recent Findings,'' Studies in the Theory of Capital Markets Praeger, New York, 47--78. [21] Ross, S. A. (1976), ``The Arbitrage Theory of Capital Asset Pricing,'' Journal of Economic Theory 13, 341--360. [22] Schwert, W. and P. Seguin (1990), ``Heteroskedasticity in Stock Returns,'' Journal of Finance 45, 1129--1155. [23] Shanken, J. (1992), ``On the Estimation of Beta--Pricing Models,'' Review of Financial Studies 5, 1--33. [24] Sharpe, W. F. (1964), ``Capital Asset Prices: A Theory of Market Equilibrium under Conditions of Risk,'' Journal of Finance 19, 425--442.
|