Paper Menu >>
Journal Menu >>
 J. Software Engineering & Applications, 2010, 3, 796-802 doi:10.4236/jsea.2010.38092 Published Online August 2010 (http://www.SciRP.org/journal/jsea) Copyright © 2010 SciRes. JSEA Contour-Based Image Segmentation Using Selective Visual Attention Engin Mendi1, Mariofanna Milanova2 1Department of Applied Science, University of Arkansas at Little Rock, Little Rock, United States; 2Department of Computer Science, University of Arkansas at Little Rock, Little Rock, United States. Email: esmendi@ualr.edu Received July 12th 2010; revised July 27th 2010; accepted August 12th 2010. ABSTRACT In many medical image segmentation applications identifying and extracting the region of interest (ROI) accurately is an important step. The usual approach to extract ROI is to apply image segmentation methods. In this paper, we focus on extracting ROI by segmentation based on visual attended locations. Chan-Vese active contour model is used for im- age segmentation and attended locations are determined by SaliencyToolbox. The implementation of the toolbox is ex- tension of the saliency map-based model of bottom-up attention, by a process of inferring the extent of a proto-object at the attended location from the maps that are used to compute the saliency map. When the set of regions of interest is selected, these regions need to be represented with the highest quality while the remaining parts of the processed image could be represented with a lower quality. The method has been successfully tested on medical images and ROIs are extracted. Keywords: Active Contours, Selective Visual Attention, Image Segmentation, Telemedicine 1. Introduction Identifying and extracting the region of interest (ROI) accurately is an important step before coding and com- pressing the image data for efficient transmission or storage. The main requirement for multimedia encod- ing techniques is achieving high level ratio of com- pression for effective use of bandwidth and energy consumption. There is an increased demand for faster transmitting diagnostic medical images in telemedicine applications. ROI must be compressed by lossless or near lossless algorithm while on the other hand, the background region must be compressed with some loss of information that is still recognizable using JP2K standard or Inverse Difference Pyramidal (IDP) de- composition (Figure 1). There are a wide variety of approaches for the seg- mentation problem. One of the popular approaches is active contour models, also called snakes. The basic idea is to start with a curve around the object to be de- tected, the curve moves towards an “optimal” position and shape by minimizing its own energy. Based on the Mumford-Shah functional [1-3] for segmentation, Chan and Vese [4] proposed a new level set model for active contours to detect objects whose boundaries are not necessarily defined by a gradient. Visual attention is the process of selecting and get- ting visual information based on saliency in the image itself (bottom-up), and on prior knowledge about scenes, objects and their interrelations (top-down) [5,6]. Visual attention addresses both problems by selectively enhancing perception at the attended location, and by successively shifting the focus of attention to multiple locations. It is also important for selecting the object of interest from the input information and [7] provides the brain with a mechanism of focusing computational resources on one object at a time, either driven by low-level image properties (bottom-up attention) or based on a specific task (top-down attention). Moving the focus of attention to locations one by one enables sequential recognition of objects at these locations. The more one knows about an image, the higher the top-down influence part will be. On the other side, for an unknown image, the bottom-up attention mechanism is very important. This is the case when no medical doctor is sending remotely the image. Hu et al. [8] used visual attention algorithm to define a method leading to the automatic choice of the best fea- tures for a given medical application. Mancas presents application of computational attention in medical images  Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 797 Figure 1. Illustration of the image decomposition called Inverse Difference Pyramid (IDP) [9] [10]. Attention may be due to: 1) local properties (a fea- ture saliency depends on its neighborhood); 2) global properties (a feature saliency depends on the whole vis- ual field). Attention model can be applied directly on the medical images in order to find rare grey level: for in- stance liver images, where only the grey level variations should be enough to detect pathologies. Here ROI was extracted with active contours based on selective visual attention. Chan-Vese active contour model is used for image segmentation and attended loca- tions are determined by SaliencyToolbox [11] which is extension of the saliency map-based model of bottom-up attention [12], by a process of inferring the extent of a proto-object at the attended location from the maps that are used to compute the saliency map. In this paper we extend our previous study of markless segmentation of medical images [13]. Here we compare results using dif- ferent local and global features for a coarse localization of possibly pathological areas. We also show the results extracting multiple ROIs in a single image. The paper is organized as follows: Section 2 provides an overview of the Chan-Vese model. Section 3 presents the bottom-up salient region selection model. Section 4 describes the application of our approach. Section 5 presents the con- clusions of this paper in a summary. 2. Chan-Vese Model The Mumford-Shah model [1-3] is a variational problem for approximating a given image by a piecewise smooth image of minimal complexity. Let u be differentiable on Rand allowed to be discontinuous across C, Mum- ford-Shah energy functional is as follows: 2 2 2 \ 1 (, )() RRC FCfdxdx C (1) where R is the image domain, f is the feature intensity, C is the curve, is the smoothed image, C is the arc length of C and , are positive parameters. Segmentation problem is restated as finding optimal ap- proximations of g by piece-wise smooth functions u, whose restrictions to the regions are differentiable. The Chan-Vese model [4] is a special case of the Mumford Shah model by restricting (1) to piece-wise constant functions and looking for the best approxi- mation of f taking only two values. Then the en- ergy functional in (1) is expressed in terms of the level set function by replacing the C by Lipschitz function : 2 12 1 (, ,)()()() R F ccHHc f 2 2 (1())() ] H cf dx (2) where H is the Heaviside function, defined by: 1, 0 () 0, 0 if z Hz if z and H is the regularization of H. Constant functions 1 c and 2 cof level sets can be ex- pressed by minimizing the energy functional with respect to the constants and keeping the level sets fixed: 1 () () () D D f Hdx c H dx (3) 2 (1( )) () (1( )) D D f Hdx c H dx (4) Combining the energy terms and replacing the singular term '()H by , the corresponding Euler-Lagrange equation for , using gradient descent in artificial time leads to: 22 12 ()[()()]cf cf t (5) where () is the curvature of the level sets and ()( )div . A multigrid scheme on the discre- tized Euler-Lagrange Equation (5) is used for the mini- mization of Chan-Vese energy functional. 12 12 ,, inf( ,,) cc F cc (6) which is 2 12 1 min(,,)[() D F ccc f 2 2 ()]cf dx (7) The explicit formula provided by (5) is solved by us-  Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 798 ing gradient descent procedure as described in [14]. 3. Bottom-Up Salient Region Selection Model The model of bottom-up salient region selection pre- sented by [7,11] based on the model of saliency-based bottom-up attention by Itti-Koch [15,16] is implemented as part of the SaliencyToolbox [11]. This model intro- duces a process of inferring the extent of a proto-object at the attended location from the maps that are used to compute the saliency map. Itti-Koch model [15,16] is a bottom-up selective visual attention based on serially scanning a saliency map that is computed from local feature contrasts, for salient loca- tions in the order of decreasing saliency (Figure 2). Pre- sented with a manually preprocessed input image, their model replicates human viewing behavior for artificial and natural scenes. Visual input [14] is first decomposed into a set of to- pographic feature maps. Different spatial locations then compete for saliency within each map, such that only locations which locally stand out from their surround can persist. All feature maps feed, in a purely bottom-up manner, into a master saliency map. The purpose of the saliency map is to represent the saliency at every location in the visual field by a scalar quantity and to guide the selection of attended locations, based on the spatial dis- tribution of saliency. However this model’s usefulness [17] as a front-end for object recognition is limited by the fact that its output is merely a pair of coordinates in the image corresponding to the most salient location. This model is extended [7,11] by a process of inferring the extent of a proto-object, contiguous region of high activity in feature map, at the attended location from the maps that are used to compute the saliency map. This is Figure 2. General architecture of Itti-Koch model [14] achieved by introducing feedback connections in the sa- liency computation hierarchy in order to estimate the proto-object region based on the maps and salient loca- tions computed in Itti-Koch model [15,16]. Different visual features that contribute to attentive selection are combined into one single topographically oriented sali- ency map which integrates the normalized information from the individual feature maps into one global measure of conspicuity. The locations [7] in the saliency map compete for the highest saliency value by means of a winner take-all (WTA) networks of integrate-and-fire neurons. The win- ning of this process is attended to, and the saliency map is inhibited. Continuing WTA competition produces the second most salient location, which is attended to subse- quently and then inhibited, thus allowing the model to simulate a scan path over the image in the order of de- creasing saliency of the attended locations. 4. Experimental Results Image segmentations of attended locations of four medi- cal images were used in the application of the new ap- proach to image segmentation. All conspicuity maps, saliency maps, WTAs and attended locations are operated by SaliencyToolbox [11]. The saliency map is summed by conspicuity maps that provide information of color, intensity and orientation. The attended locations are set as initial contours to be segmented by using Chan-Vese Model [4]. For example, in Figure 3, seborrheic keratosis is seg- mented from a skin image. Figure 4 shows multiple bas- al cell carcinoma segmentation. Figure 5 and Figure 6 show segmentation of cherry angiomas of the trunk and basal cell carcioma of the cheek, respectively. Table 1 shows the stimulated time (ms) that attended locations (AL) took. Global low level attention is applied directly on the medical images. Low level features bring some top down information about grey levels. A final attention map, for example Figure 3(g), can help the contour seg- mentation algorithm by focusing only at separated re- gions with the greatest chance of being pathological. This approach works on the images where pathological pixel grey level is different from normal tissues grey-level. For telemedicine applications, we have integrated im- age segmentation with adaptive compression technique. The proposed compression technique is based on the hypothesis that image resolution exponentially decreases from the fovea to the retina periphery. This hypothesis Table 1. Simulated time (ms) of attended locations 1st AL 2nd AL 3rd AL 4th AL Figure 3 239,98 Figure 4 39,171 200,151 Figure 5 174,193 72,18 Figure 6 98,189 157,132 167,242 185,115 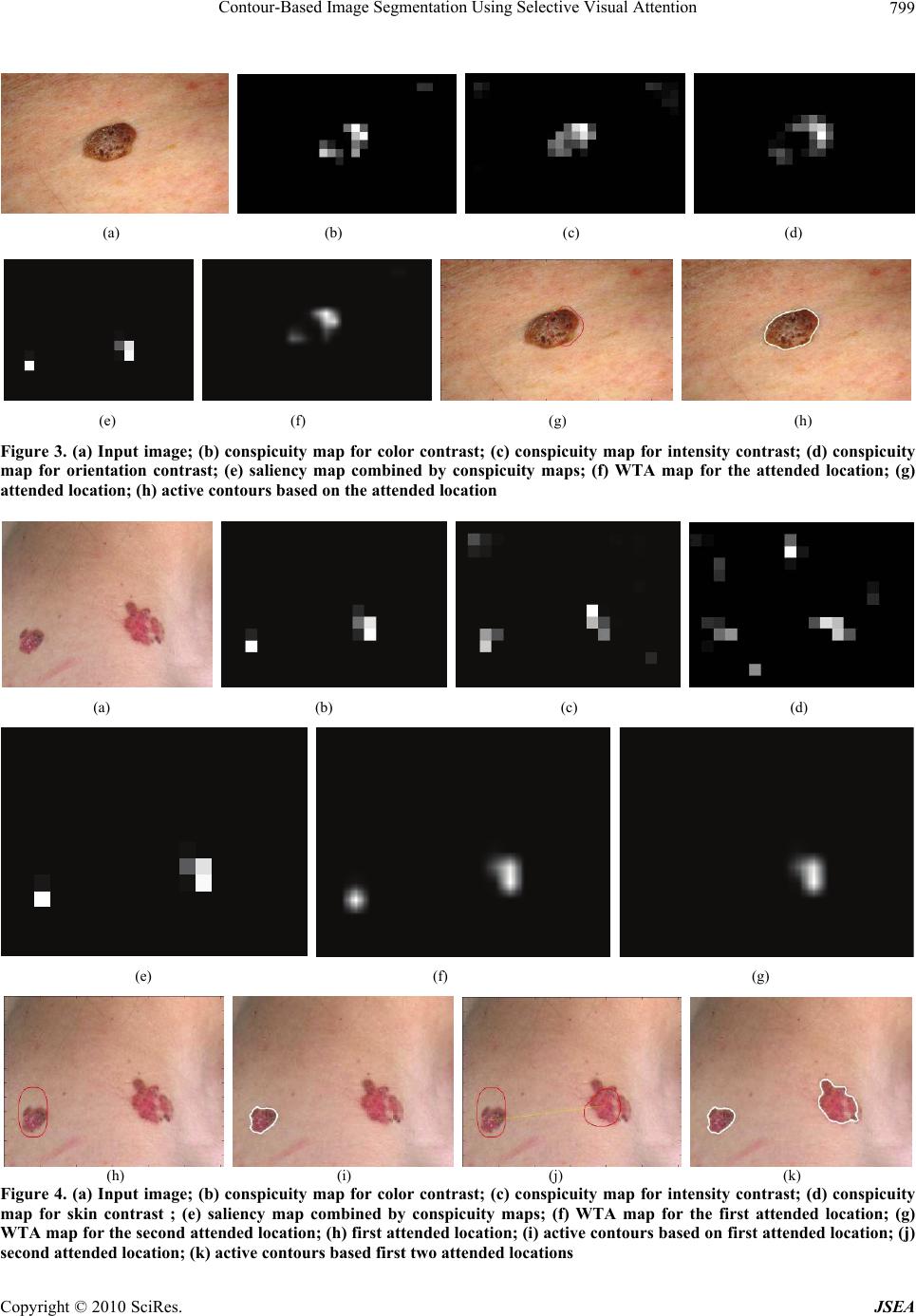 Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 799 (a) (b) (c) (d) (e) (f) (g) (h) Figure 3. (a) Input image; (b) conspicuity map for color contrast; (c) conspicuity map for intensity contrast; (d) conspicuity map for orientation contrast; (e) saliency map combined by conspicuity maps; (f) WTA map for the attended location; (g) attended location; (h) active contours based on the attended location (a) (b) (c) (d) (e) (f) (g) (h) (i) (j) (k) Figure 4. (a) Input image; (b) conspicuity map for color contrast; (c) conspicuity map for intensity contrast; (d) conspicuity map for skin contrast ; (e) saliency map combined by conspicuity maps; (f) WTA map for the first attended location; (g) WTA map for the second attended location; (h) first attended location; (i) active contours based on first attended location; (j) second attended location; (k) active contours based first two attended locations 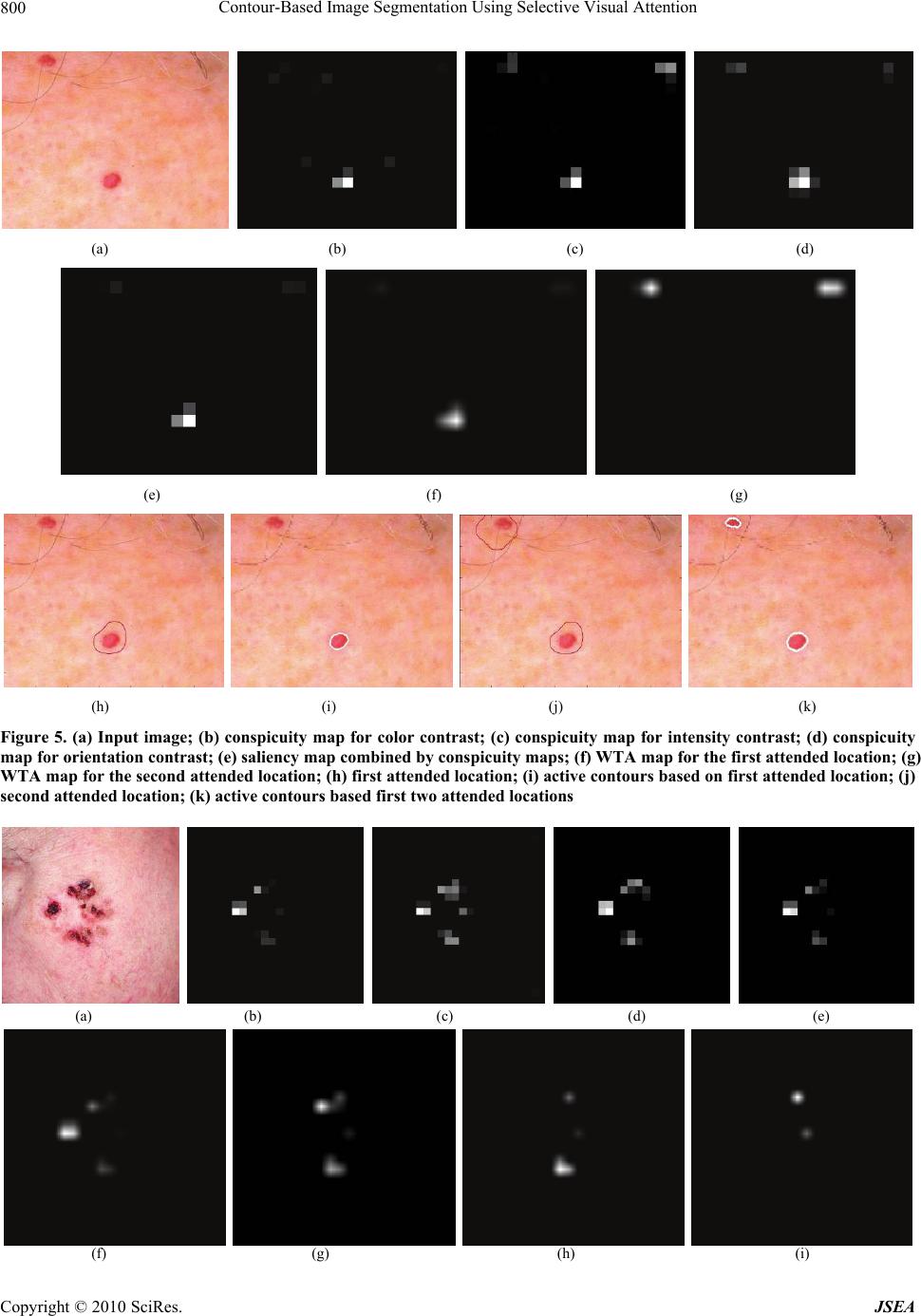 Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 800 (a) (b) (c) (d) (e) (f) (g) (h) (i) (j) (k) Figure 5. (a) Input image; (b) conspicuity map for color contrast; (c) conspicuity map for intensity contrast; (d) conspicuity map for orientation contrast; (e) saliency map combined by conspicuity maps; (f) WTA map for the first attended location; (g) WTA map for the second attended location; (h) first attended location; (i) active contours based on first attended location; (j) second attended location; (k) active contours based first two attended locations (a) (b) (c) (d) (e) (f) (g) (h) (i) 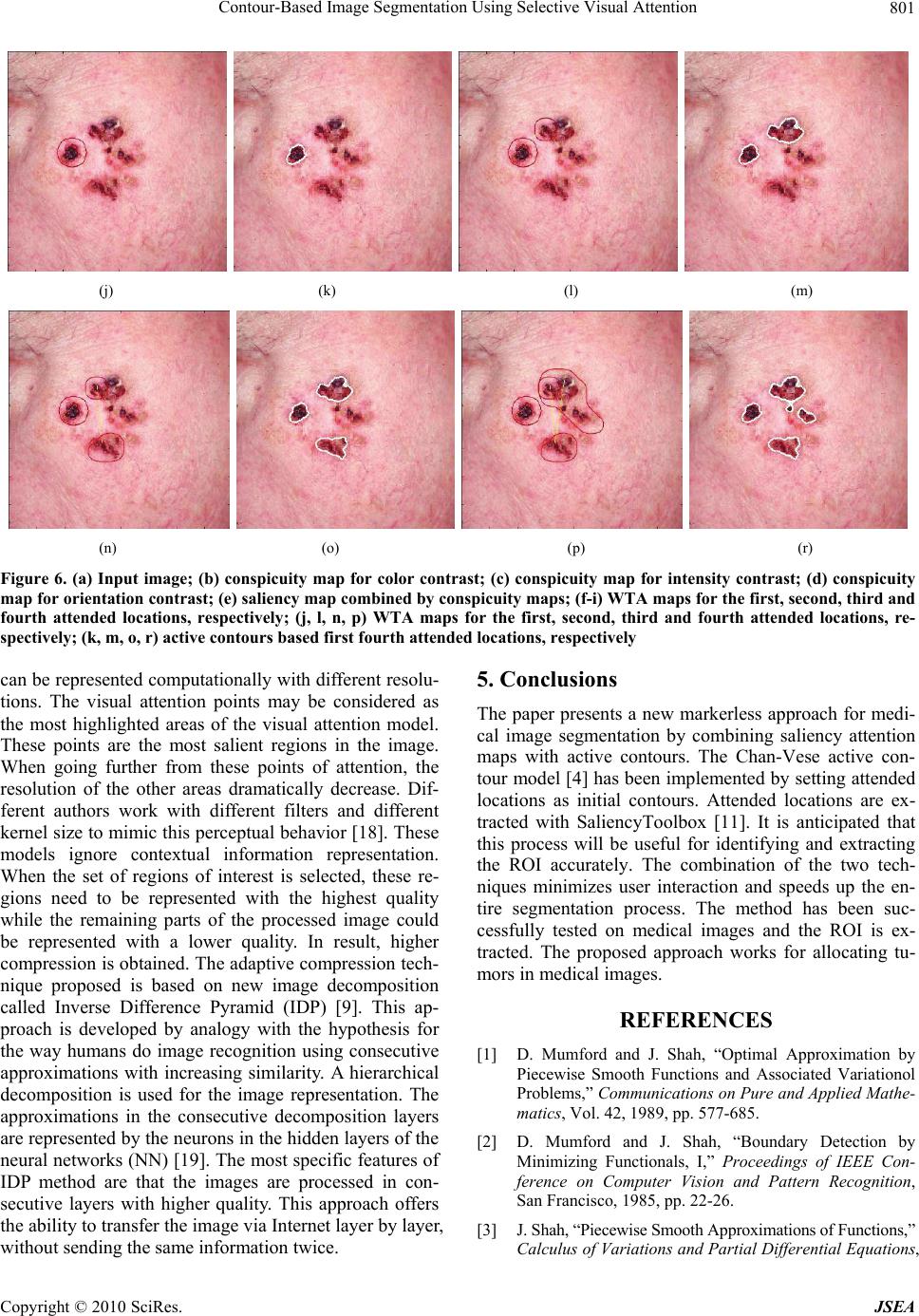 Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 801 (j) (k) (l) (m) (n) (o) (p) (r) Figure 6. (a) Input image; (b) conspicuity map for color contrast; (c) conspicuity map for intensity contrast; (d) conspicuity map for orientation contrast; (e) saliency map combined by conspicuity maps; (f-i) WTA maps for the first, second, third and fourth attended locations, respectively; (j, l, n, p) WTA maps for the first, second, third and fourth attended locations, re- spectively; (k, m, o, r) active contours based first fourth attended locations, respectively can be represented computationally with different resolu- tions. The visual attention points may be considered as the most highlighted areas of the visual attention model. These points are the most salient regions in the image. When going further from these points of attention, the resolution of the other areas dramatically decrease. Dif- ferent authors work with different filters and different kernel size to mimic this perceptual behavior [18]. These models ignore contextual information representation. When the set of regions of interest is selected, these re- gions need to be represented with the highest quality while the remaining parts of the processed image could be represented with a lower quality. In result, higher compression is obtained. The adaptive compression tech- nique proposed is based on new image decomposition called Inverse Difference Pyramid (IDP) [9]. This ap- proach is developed by analogy with the hypothesis for the way humans do image recognition using consecutive approximations with increasing similarity. A hierarchical decomposition is used for the image representation. The approximations in the consecutive decomposition layers are represented by the neurons in the hidden layers of the neural networks (NN) [19]. The most specific features of IDP method are that the images are processed in con- secutive layers with higher quality. This approach offers the ability to transfer the image via Internet layer by layer, without sending the same information twice. 5. Conclusions The paper presents a new markerless approach for medi- cal image segmentation by combining saliency attention maps with active contours. The Chan-Vese active con- tour model [4] has been implemented by setting attended locations as initial contours. Attended locations are ex- tracted with SaliencyToolbox [11]. It is anticipated that this process will be useful for identifying and extracting the ROI accurately. The combination of the two tech- niques minimizes user interaction and speeds up the en- tire segmentation process. The method has been suc- cessfully tested on medical images and the ROI is ex- tracted. The proposed approach works for allocating tu- mors in medical images. REFERENCES [1] D. Mumford and J. Shah, “Optimal Approximation by Piecewise Smooth Functions and Associated Variationol Problems,” Communications on Pure and Applied Mathe- matics, Vol. 42, 1989, pp. 577-685. [2] D. Mumford and J. Shah, “Boundary Detection by Minimizing Functionals, I,” Proceedings of IEEE Con- ference on Computer Vision and Pattern Recognition, San Francisco, 1985, pp. 22-26. [3] J. Shah, “Piecewise Smooth Approximations of Functions,” Calculus of Variations and Partial Differential Equations,  Contour-Based Image Segmentation Using Selective Visual Attention Copyright © 2010 SciRes. JSEA 802 Vol. 2, 1994, pp. 315-328. [4] T. F. Chan and L. A. Vese, “Active Contours without Edges,” IEEE Transactions on Image Processing, Vol. 10, No. 2, 2001, pp. 266-277. [5] D. Walters, U. Rutishauser, C. Koch and P. Perona, “Selective Visual Attention Enables Learning and Recognition of Multiple Objects in Cluttered Scenes,” Computer Vision and Image Understanding, Vol. 100, No. 1-2, 2005, pp. 41-63. [6] M. Milanova, S. Rubin, R. Kountchev, V. Todorov and R. Kountcheva, “Combined Visual Attention Model for Video Sequences,” IEEE ICPR’2008 International Con- ference on Pattern Recognition, Tampa, 2008, pp. 1-4. [7] D. Walter, “Interactions of Visual Attention and Object Recognition: Computational Modeling, Algorithms, and Psychophysics,” PhD Thesis, California Institute of Technology, Pasadena, 2006. [8] X.-P. Hu, “Hot Spot Detection based on Feature Space Representation of Visual Search,” IEEE Transactions on Medical Images, Vol. 22, No. 9, 2003, pp. 1152-1162. [9] A. Kountchev and A. Mironov, “Algorithms for Pyramid Image Decomposition,” In: N. Mastorakis Ed., Intelligent Systems and Computer Science, WSEAS Press, Danvers, 1999, pp. 196-200. [10] M. Mancas, “Image Perception: Relative Influence of Bottom-Up and Top-Down Attention,” Attention in Cog- nitive Systems, Lecture Notes in Computer Science, Vol. 5395, Greece, 2008, pp. 212-226. [11] D. Walther and C. Koch, “Modeling Attention to Salient Proto-Objects,” Neural Networks, Vol. 19, No. 9, 2006, pp. 1395-1407. [12] C. Koch and S. Ullman, “Shifts in Selective Visual- Attention—Towards the Underlying Neural Circuitry,” Human Neurobiology, Vol. 4, No. 4, 1985, pp.219-227. [13] E. Mendi and M. Milanova, “Image Segmentation with Active Contours Based on Selective Visual Attention,” 8th WSEAS International Conference on Signal Pro- cessing (SIP’09), Istanbul, 2009, pp. 79-84. [14] K. Fundana, N. C. Overgaard and A. Heyden, “Deformable Shape Priors in Chan-Vese Segmentation of Image Sequences,” Proceedings International Conference on Image Processing, San Antonio, Vol. 1, 2007, pp. 285- 288. [15] L. Itti, C. Koch and E. Niebur, “A Model of Saliency-Based Visual Attention for Rapid Scene Analysis,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 20, No. 11, 1998, pp. 1254- 1259. [16] C. Koch and L. Itti, “Computational Modeling of Visual Attention,” Nature Reviews Neuroscience, Vol. 2, 2001, pp. 194-203. [17] D. Walther, U. Rutishauser, C. Koch and P. Perona, “On the Usefulness of Attention for Object Recognition,” Workshop on Attention and Performance in Compu- tational Vision at ECCV, Prague, 2004, pp. 96- 103. [18] M. Mancas, B. Gosselin and B Macq, “Perceptual Image Representation,” EURASIP Journal of Image and Video Processing, Vol. 2007, 2007, pp. 1-9. [19] R. Kountchev, S. Rubin, M. Milanova, V. Todorov and R. Kountcheva, “Non-Linear Image Representation Based on IDP with NN,” WSEAS Transactions on Signal Proc- essing, Istanbul, Vol. 5, No. 9, 2009, pp. 315-325. |