Q. Q. SUN ET AL. 249
resul
ages and the
co
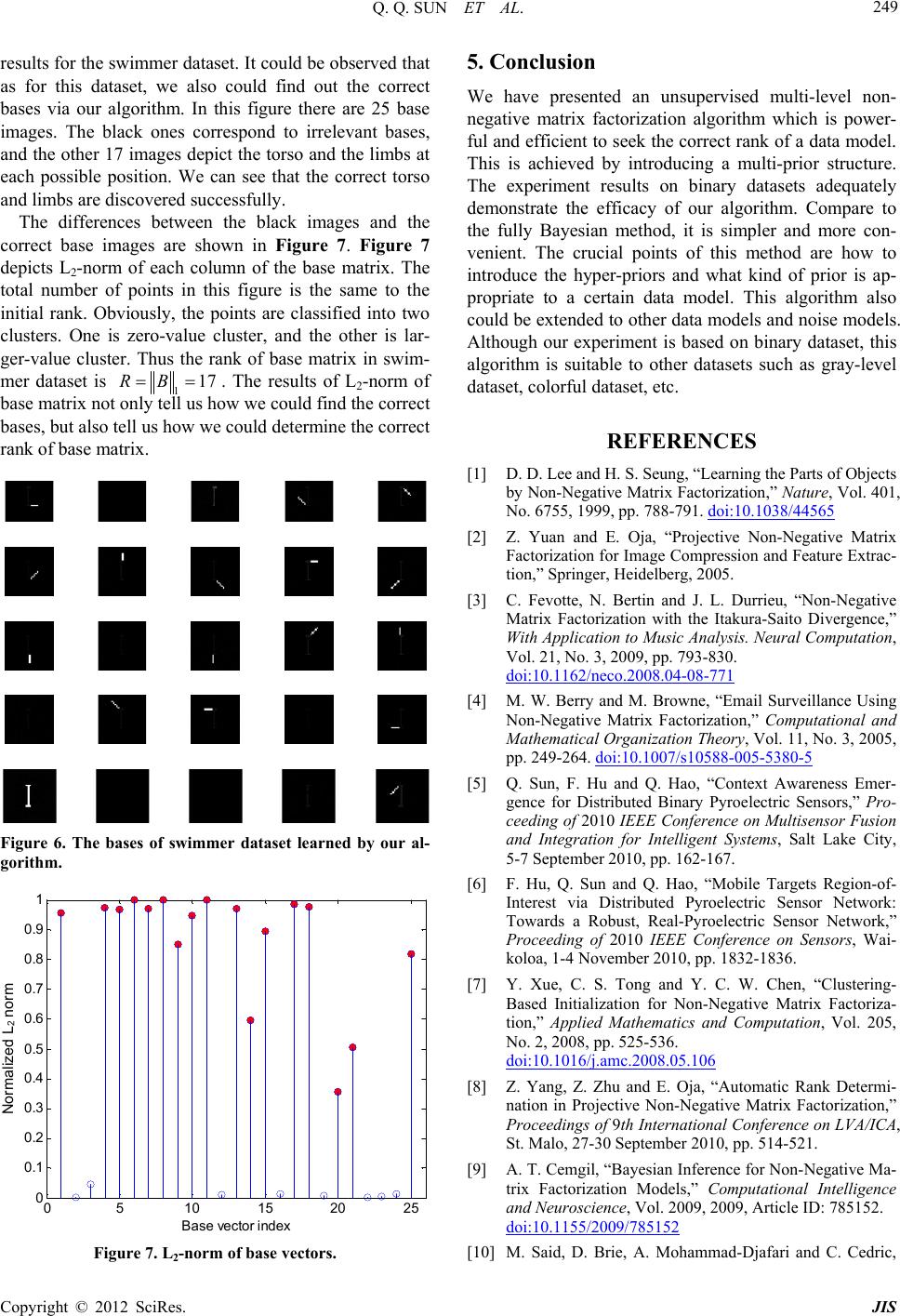
ts for the swimmer dataset. It could be observed that
as for this dataset, we also could find out the correct
bases via our algorithm. In this figure there are 25 base
images. The black ones correspond to irrelevant bases,
and the other 17 images depict the torso and the limbs at
each possible position. We can see that the correct torso
and limbs are discovered successfully.
The differences between the black im
rrect base images are shown in Figure 7. Figure 7
depicts L2-norm of each column of the base matrix. The
total number of points in this figure is the same to the
initial rank. Obviously, the points are classified into two
clusters. One is zero-value cluster, and the other is lar-
ger-value cluster. Thus the rank of base matrix in swim-
mer dataset is 117RB. The results of L2-norm of
base matrix not ow we could find the correct
bases, but also tell us how we could determine the correct
rank of base matrix.
only tell us h
Figure 6. The bases of swimmer dataset learned by our al-
gorithm.
05 10 15 20 25
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Base ve ctor inde
Norm alized L2 nor m
Normalized L
2
norm
Figure 7. L2-norm of base vectors.
supervised multi-level non-
[1] D. D. Lee andhe Parts of Objects
5. Conclu
We have presented an un
sion
negative matrix factorization algorithm which is power-
ful and efficient to seek the correct rank of a data model.
This is achieved by introducing a multi-prior structure.
The experiment results on binary datasets adequately
demonstrate the efficacy of our algorithm. Compare to
the fully Bayesian method, it is simpler and more con-
venient. The crucial points of this method are how to
introduce the hyper-priors and what kind of prior is ap-
propriate to a certain data model. This algorithm also
could be extended to other data models and noise models.
Although our experiment is based on binary dataset, this
algorithm is suitable to other datasets such as gray-level
dataset, colorful dataset, etc.
REFERENCES
H. S. Seung, “Learning t
by Non-Negative Matrix Factorization,” Nature, Vol. 401,
No. 6755, 1999, pp. 788-791. doi:10.1038/44565
[2] Z. Yuan and E. Oja, “Projective Non-Negative Matrix
urrieu, “Non-Negative
Factorization for Image Compression and Feature Extrac-
tion,” Springer, Heidelberg, 2005.
[3] C. Fevotte, N. Bertin and J. L. D
Matrix Factorization with the Itakura-Saito Divergence,”
With Application to Music Analysis. Neural Computation,
Vol. 21, No. 3, 2009, pp. 793-830.
doi:10.1162/neco.2008.04-08-771
[4] M. W. Berry and M. Browne, “Email Surveillance Using
Non-Negative Matrix Factorization,” Computational and
Mathematical Organization Theory, Vol. 11, No. 3, 2005,
pp. 249-264. doi:10.1007/s10588-005-5380-5
[5] Q. Sun, F. Hu and Q. Hao, “Context Awareness Emer-
ile Targets Region-of-
“Clustering-
06
gence for Distributed Binary Pyroelectric Sensors,” Pro-
ceeding of 2010 IEEE Conference on Multisensor Fusion
and Integration for Intelligent Systems, Salt Lake City,
5-7 September 2010, pp. 162-167.
[6] F. Hu, Q. Sun and Q. Hao, “Mob
Interest via Distributed Pyroelectric Sensor Network:
Towards a Robust, Real-Pyroelectric Sensor Network,”
Proceeding of 2010 IEEE Conference on Sensors, Wai-
koloa, 1-4 November 2010, pp. 1832-1836.
[7] Y. Xue, C. S. Tong and Y. C. W. Chen,
Based Initialization for Non-Negative Matrix Factoriza-
tion,” Applied Mathematics and Computation, Vol. 205,
No. 2, 2008, pp. 525-536.
doi:10.1016/j.amc.2008.05.1
utomatic Rank Determi-
ative Ma-
[8] Z. Yang, Z. Zhu and E. Oja, “A
nation in Projective Non-Negative Matrix Factorization,”
Proceedings of 9th International Conference on LVA/ICA,
St. Malo, 27-30 September 2010, pp. 514-521.
[9] A. T. Cemgil, “Bayesian Inference for Non-Neg
trix Factorization Models,” Computational Intelligence
and Neuroscience, Vol. 2009, 2009, Article ID: 785152.
doi:10.1155/2009/785152
[10] M. Said, D. Brie, A. Mohammad-Djafari and C. Cedric,
Copyright © 2012 SciRes. JIS




