SEDSR: Soft Error Detection Using Software Redundancy 665
N parallel modules in order to do the operation and
compare their results with each other. This technique has
about 100(N − 1)% memory and performance overhead
and its fault coverage is about 100% [4]. The later stores
multiple copies of the program in the memory and
compares their results with each other. Some solutions
based on information redundancy can be found in [5,6].
These methods generally replicate the whole program
and compare their results with each other. The com-
parison instructions are inserted in different places of the
program in various methods.
The mentioned methods are widely used for control
flow and data errors detection. These methods are eva-
luated and compared with each other by fault injection.
As mentioned, by the technology progress and reduction
of electronic equipment dimensions, delivering a method
that is able to have good fault coverage by an acceptable
overhead impose on memory and performance is very
important. The parameters of memory consumption and
execution time of a program is as important as fault
coverage of a method nowadays. Other methods of this
field do not meet these three parameters simultaneously.
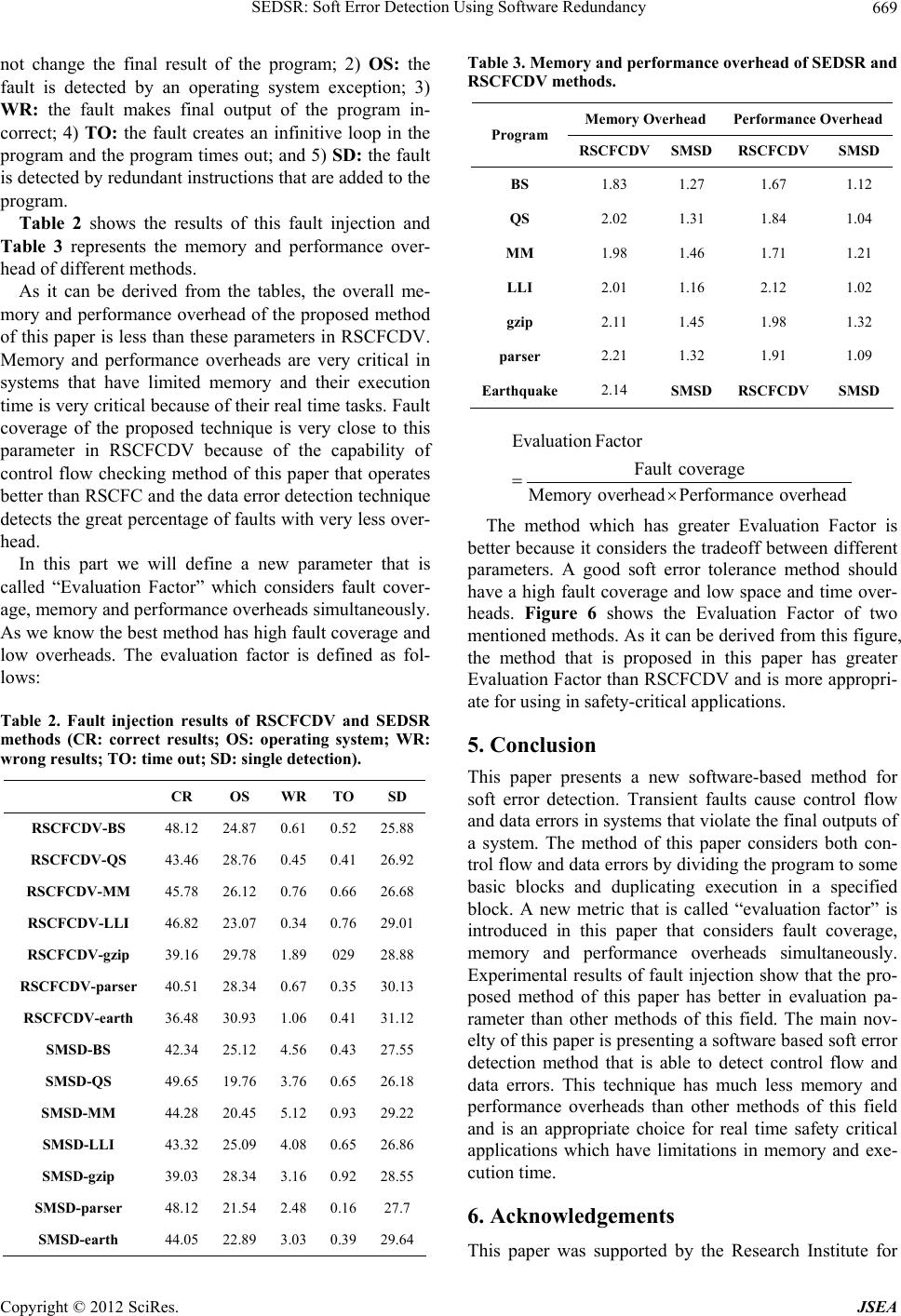
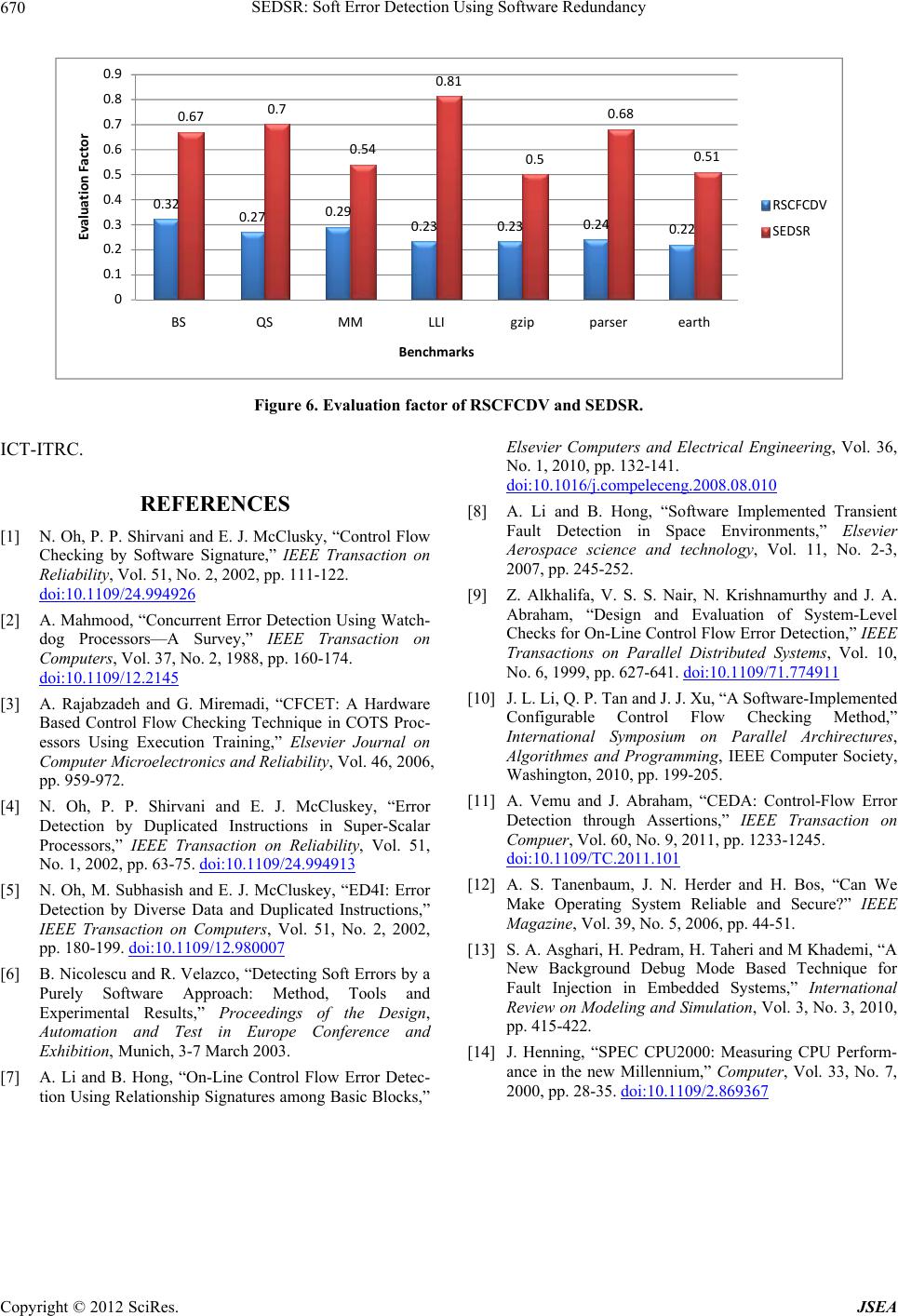
To meet all of the parameters, in this paper, a factor that
is called “Evaluation Factor” is introduced and used for
different methods comparison.
SEDSR that is presented in this paper first uses a
control flow checking method that assigns a signature
and some redundant instructions to each basic block.
Then it duplicates a block which is called critical because
of its effect on the other blocks. This method has accept-
able fault coverage and its time/space overhead is less
than 100% which is better than the previous presented
methods of this field.
The reminder of this paper is organized as follows. In
the second section of this paper, our motivation of pre-
senting this method and the experimental conditions will
be explained. The third section introduces the proposed
method and the evaluation results and SEDSR compari-
son with other techniques is presented in the forth sec-
tion.
2. Motivation
Usually, transient faults that occur in computer systems
cause control flow checking or data errors. Data errors
change the value of a variable in the program and control
flow errors change the running flow of a program.
Soft errors which are mainly because of single event
upsets (SEUs) are caused because of electromagnetic
interference, power glitch or strikes on a chip. These
kinds of errors are very serious and can interrupt the
functionality of a program. So exploiting a method for
soft error detection is needed in many applications which
are using Commercial Off-The Shelf (COTS) equipment.
A control flow error occurrence in a program can be
modeled by the following situations:
Branch deletion: in this case a branch in the program
will be missed.
Branch modification: in this case the condition or
destination of a branch in the program is changed.
Branch insertion: in this case the program jumps to
an illegal point.
Program counter manipulation: in this case the
program counter of a program is changed randomly
and leads to random jumps.
The method of this paper can detect control flow and
data errors simultaneously and force less overhead on
memory and execution time of the program. The previ-
ous techniques have not considered these parameters
with each other and usually focus on fault coverage
rather than memory and performance overheads. Time/
space overhead is as important as fault coverage and
should be considered in different methods precisely. The
contributions of this paper can be listed as follows:
Presenting a new control flow checking method
which has better fault coverage, memory and per-
formance overhead than other techniques.
Presenting a new data error detection method that
limits the overhead of replication and repeats more
critical variables instead of the whole program. In this
way, the tradeoff between memory, performance
overhead and fault coverage will be satisfied better
than full duplication methods.
Combining the former methods with each other to
construct a soft error tolerant system that detects
about 96.3% of the errors and forces less than 80%
memory and performance overhead to the system.
Introducing a new parameter which is called “evalua-
tion factor” and considers fault coverage, memory
and performance overhead simultaneously.
In the next section, the proposed method of this paper
will be explained.
3. The Proposed Technique
3.1. Description of Control Flow Error Detection
Method
In the previous sections, the basic idea of control flow
checking methods is explained. Because of advantages of
software-based techniques, the method of this paper is in
this category. Like other control flow checking methods,
this technique divides the program into some basic
blocks and assigns a signature to each block based on its
location in control flow graph. A basic block is consisted
of maximum number of instructions which are run
continuously. Therefore, the instructions of basic blocks
are not branches or destination of branch instructions. In
this way the program P can be shown as a graph which
Copyright © 2012 SciRes. JSEA