Health
Vol.5 No.11(2013), Article ID:39453,8 pages DOI:10.4236/health.2013.511235
Determinants of infant mortality in rural India: A three-level model
![]()
1Department of Biostatistics, All India Institute of Medical Sciences (AIIMS), New Delhi, India; *Corresponding Author: dwivedi7@hotmail.com
2National Institute of Medical Statistics, Indian Council of Medical Research, New Delhi, India
Copyright © 2013 Sada Nand Dwivedi et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Received 29 August 2013; revised 29 September 2013; accepted 15 October 2013
Keywords: Infant Mortality; Hierarchical Structure; National Family Health Survey; State Level; District Level; Public Health; Multilevel Logistic Regression; Traditional Logistic Regression
ABSTRACT
Taking into account the hierarchical structure of the data, through two-level analysis on infant mortality available under second round of National family Health Survey, the same group of authors recently reported determinants of infant mortality while examining possible changes in results under traditional regression analysis that ignores hierarchical structure of data. They reported that the community (e.g., state) level characteristics still have a major role regarding infant mortality in India. For better epidemiological understanding, the present study is to assess determinants of infant mortality in rural India, where three level considerations were possible. The results indicate that even after consideration of these covariates, variation in infant mortality remains significant not only between States but also between Districts. Further, as an additional observation, the probability of infant mortality is still high in rural areas of districts having health facility beyond three kilometers than their counterparts.
1. INTRODUCTION
The infant mortality rate (IMR) still remains an important public health indicator [2,3]. Its data structures are often hierarchical in nature, especially those available at national/state/district/village/household/individual level [1-5]. Hence, as reported earlier, data on IMR need to be dealt with hierarchical/multilevel analysis that takes hierarchical structure into account and also makes it possible to incorporate variables from all levels and retains them at their own levels [1]. Depending on circumstances, there may be various possible approaches while analyzing such data [1-27]. However, for better epidemiological understanding in rural areas where the largest population of the country lives, data relate to only rural India. The analytical methods involved a three-level model instead of earlier two-level models [1]. At regional level, an appropriate epidemiological understanding from time to time may be helpful to policy planners. It may also help in testing many hypotheses related to population issues and generate various important clues towards public health programs.
2. MATERIALS AND METHODS
2.1. Materials
The data used in the present study are from the National Family Health Survey (NFHS), 1998-1999, conducted for the second time in India. The details about sampling methods, used questionnaires, methods of data collection and all other aspects are already documented [1,6]. The detailed information on antenatal, delivery and postnatal care was obtained for the two most recent births that occurred to eligible women during the three years preceding the survey. For analysis, to restore the correct proportion in view of no self-weighting of the sample design, the country-level weight was used [1]. As considered earlier [1], in present analysis also, infant mortality was taken as dependent variable (i.e., child who died before his/her first birthday) in the last three years preceding the survey (0 = alive, died = 1). Only from rural area, a total 24,493 births were recorded in the last three years preceding the survey. Out of them, a total of 192 children who died after their first birthday were considered as alive. Further, a total of 7920 children who had not completed their first birthday and were alive were excluded from the analysis. The problem of missing information also resulted into exclusion of some of the children: religion + caste (144), standard of living index (199), place of delivery (82), size of child at birth (86), squeeze milk from breast (120), mother’s education level (3), father’s education level (40), consumed all given tablets (78), distance to nearest health facility 68, and Delhi-rural (54). Finally, complete information on 15,969 children was available for analysis.
As considered earlier [1], a number of explanatory variables were selected for the analysis; they are presented here again for completeness. Among the qualitative variables, some of them were retained in their existing forms: place of residence (urban/rural), standard of living index (high/low/medium), sex of the child (girl/ boy), consumed all given iron tablets (yes/no), and child received colostrums (yes/no). Further, to enable a meaningful analysis, some of the variables available in the form of nominal scale were categorized as dichotomous variables after exploratory analysis: size at birth (averge + large/small), status of birth (single/multiple), mother received at least 3 antenatal visits (yes/no), received at least 2 TT dose (yes/no), place of delivery (institutional/ non-institutional). To derive meaningful information, continuous variables were converted into categorical variables, like preceding birth interval (≥24 months/first birth/≤24 months), mother education level (9 & above/0 - 5/6 - 8), father’s years of schooling (9 & above/0 - 5/6 - 8), and birth order (2 - 3/1/4+). Further, some of the variables were generated using available information in multiple forms. For example, exposure to radio, television, newspaper and poster in the last month preceding the survey were collected separately. Mothers were categorized as positive if they were exposed to any of the media listed above, otherwise no and variable was named as exposure to mass media (yes/no). Further, mothers age at birth was computed by subtracting date of birth of child and date of birth of mother, and recoded as (20 - 29/<20/30 +). Religion and caste were pooled to derive another variable religion-caste (non-Hindu/SC-ST-OBC Hindu/other Hindu). At state level, percentage of women aware of ORS (<63/≥63); percentage of births of order 4 and above (<28/≥28); percentage of women with middle school & above (<20/≥20); Government expenditure on health per head (<29/≥29) and percentage of women with any anemia (<48/≥49), were considered. For such considerations, confidence interval (CI) of each of the considered covariates’ national level estimate was calculated and the lower limit of CI was used as threshold for categorization [1]. Further, in analysis of rural data, one additional covariate namely district with health facility within 3 km was also considered.
2.2. Analytical Methods
For the considered data set for rural India, to begin with, the distribution of children in relation to various covariates and also corresponding percentage of infant mortality were tabulated. Because outcome variable “infant mortality” is binary, under traditional data analysis, logistic regression analysis was used to find out the individual factors associated with infant mortality. Accordingly, unadjusted risk ratio and its 95% confidence interval (CI) were worked out in relation to each covariate and presented in the corresponding tables.
As reported earlier [1], the sets of covariates in data analysis were considered in view of both statistical and public health relevance. Further, on exploration, presence of co linearity and also effects modification among the considered covariates was not noticed in the data sets. As appropriate traditional data analysis, stepwise logistic regression analysis was used to find out the factors associated with infant mortality without (TLR1) and with (TLR2) consideration of district level variable. Again, for appropriate comparison, the respective covariates that were retained in the traditional logistic regression models (TLR2) were included in the hierarchical models (MLR1 & MLR2). Finally, adjusted risk ratio and its 95% confidence interval were presented in the corresponding tables.
As opposed to earlier study [1], exploration of data structure on infant mortality in rural India revealed appropriateness of consideration of three-level structure in the analysis, conceptualized as children (at level-1) nested within districts (at level-2) and districts nested within states (at level-3). In addition to traditional multivariable stepwise logistic regression analysis (TLR2), the multilevel analysis was carried out twice: first as random intercept model (MLR1) and second as random intercept as well as slope model (MLR2). In other words, all the community level variables were retained at fixed level under MLR1 where as at random level under MLR2. The used models are simply extension of those described earlier [1], from two-level to three levels. To remind again, the hierarchical models correctly assume that children/mothers in same district and districts in state are correlated in terms of community effects, which is not true under traditional logistic regression model.
As documented earlier [1], under the traditional discrete response logistic regression models, usually computationally friendly method of estimation “maximum likelihood” is used. However, this procedure becomes intensive for discrete response multilevel models. Hence, the multilevel models were estimated using either the iterative generalized least squares (IGLS) or reweighted IGLS using MLwiN program version 1.1. For this, Marginal Quasi Likelihood (MQL) approximation with a first order Taylor linearization followed by the 2nd order PQL procedure was applied. To assess significance of the coefficients, the Wald test was used. Considering significant association at 5% level of significance, the coefficients were transformed to obtain risk ratio and its 95% CI. All analyses were carried out using STATA (version 9) and SPSS (version 14), other than multilevel models. The detailed results related to infant mortality in rural India are presented in Tables 1 and 2.
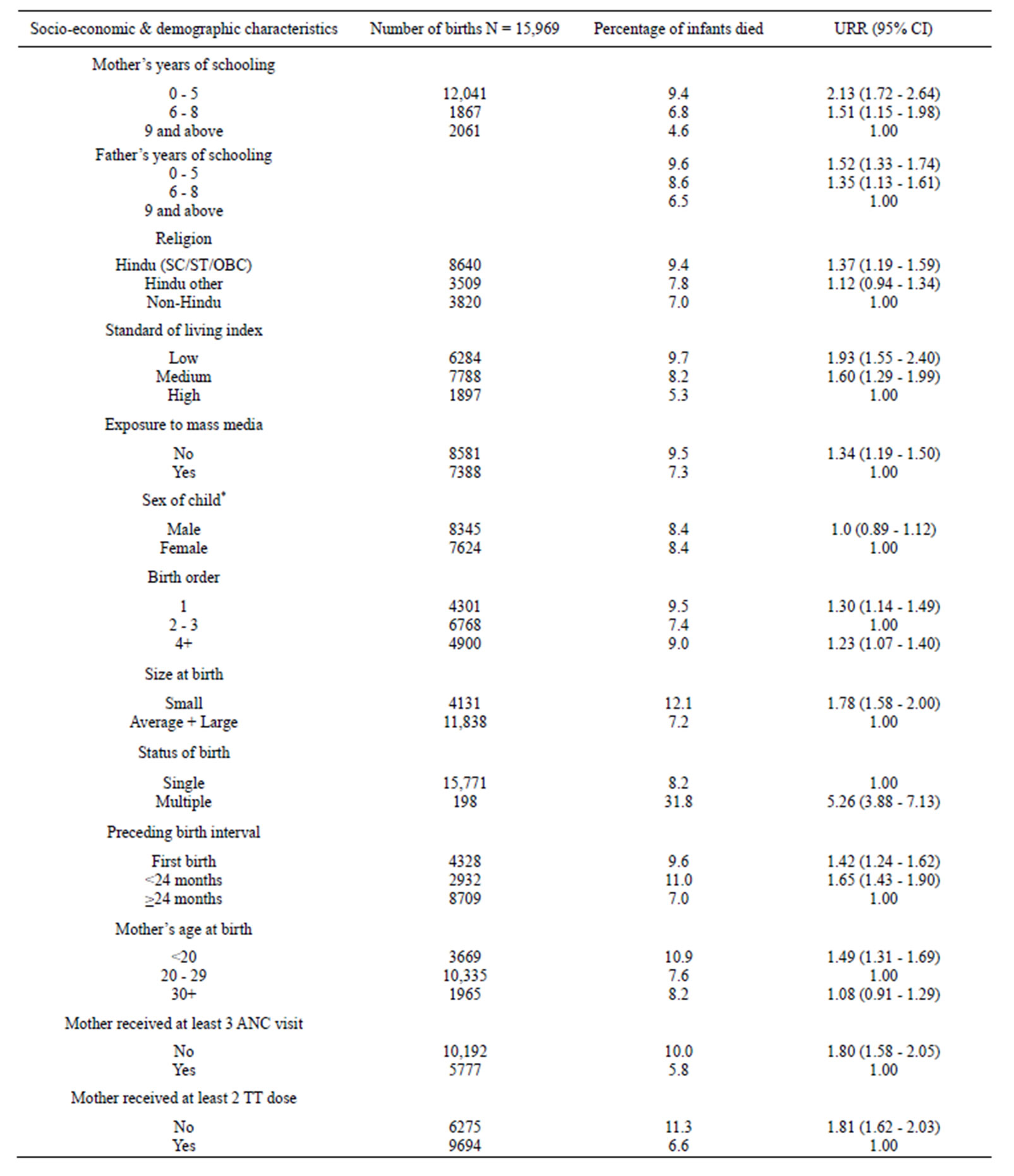
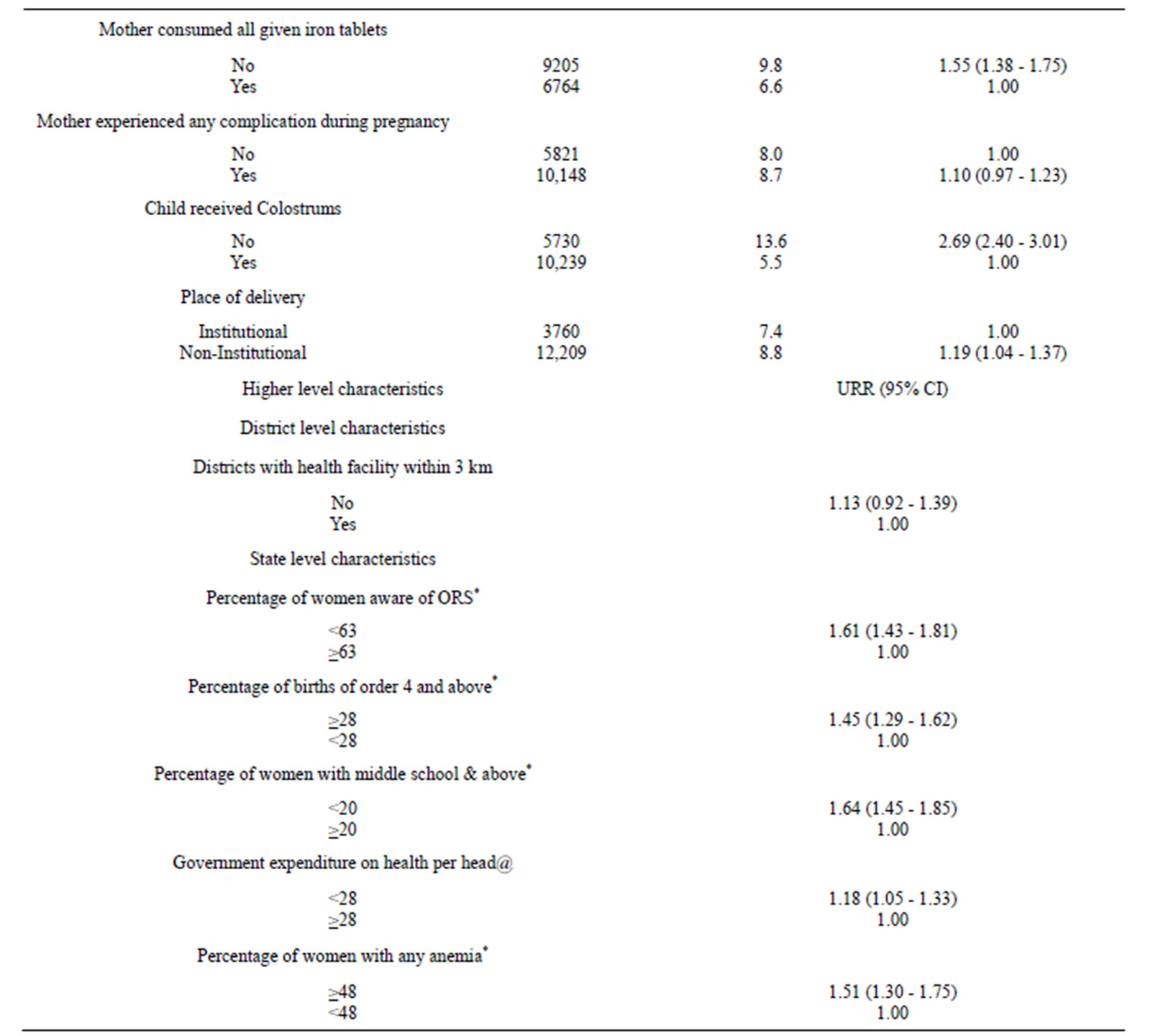
Table 1. Percentage of infants died according to their socioeconomic & demographic characteristics in Rural India and related unadjusted risk ratio (URR) and corresponding 95% confidence interval (95% CI).
Continued
*Percentage are taken from the NFHS-2, India report @state-wise population from 1991 census; and expenditure on health: tenth five year plan 2002-2007, Planning Commission of India.
3. RESULTS
As true in case of infant mortality in India [1], the distribution of infant deaths in the relation to various socioeconomic and demographic characteristics in rural India (Table 1) also reveals that those children are more likely to die before celebrating their first birthday; whose mothers have comparatively lower education [2.13 (1.72 - 2.64)]; did not have exposure to mass media [1.34 (1.19 - 1.50)]; fathers also have low level of education [1.52 (1.33 - 1.74)]; who belong to SC/ST/OBC categories [1.37 (119 - 1.59)], low and medium standard of living index 1.93 (1.55 - 2.40)]; births order one [1.30 (1.14 1.49)] and also 4 and above [1.23 (1.07 - 1.40)]; whose size at birth is small [1.78 (1.58 - 2.00)]; who are multiple at birth [5.26 (3.88 - 7.13)]; who are either first birth [1.42 (1.24 - 1.62)] or born before 24 months of previous child [1.65 (1.43 - 1.90)]; whose mothers are youngsters below 20 years of age [1.49 (131 - 1.69)]; whose mother did not receive three ANC visits for check up [1.80 (1.58 - 2.05)]; and also did not receive two TT dose [1.81 (1.62 - 2.03)]; whose mothers could not consume all given iron tables during pregnancy [1.55 (1.38 - 1.75)]; whose mothers delivered the child at non-institutional place [1.19 (1.04 - 1.37)]; and who did not receive colostrums [2.69 (2.40 - 3.01)].
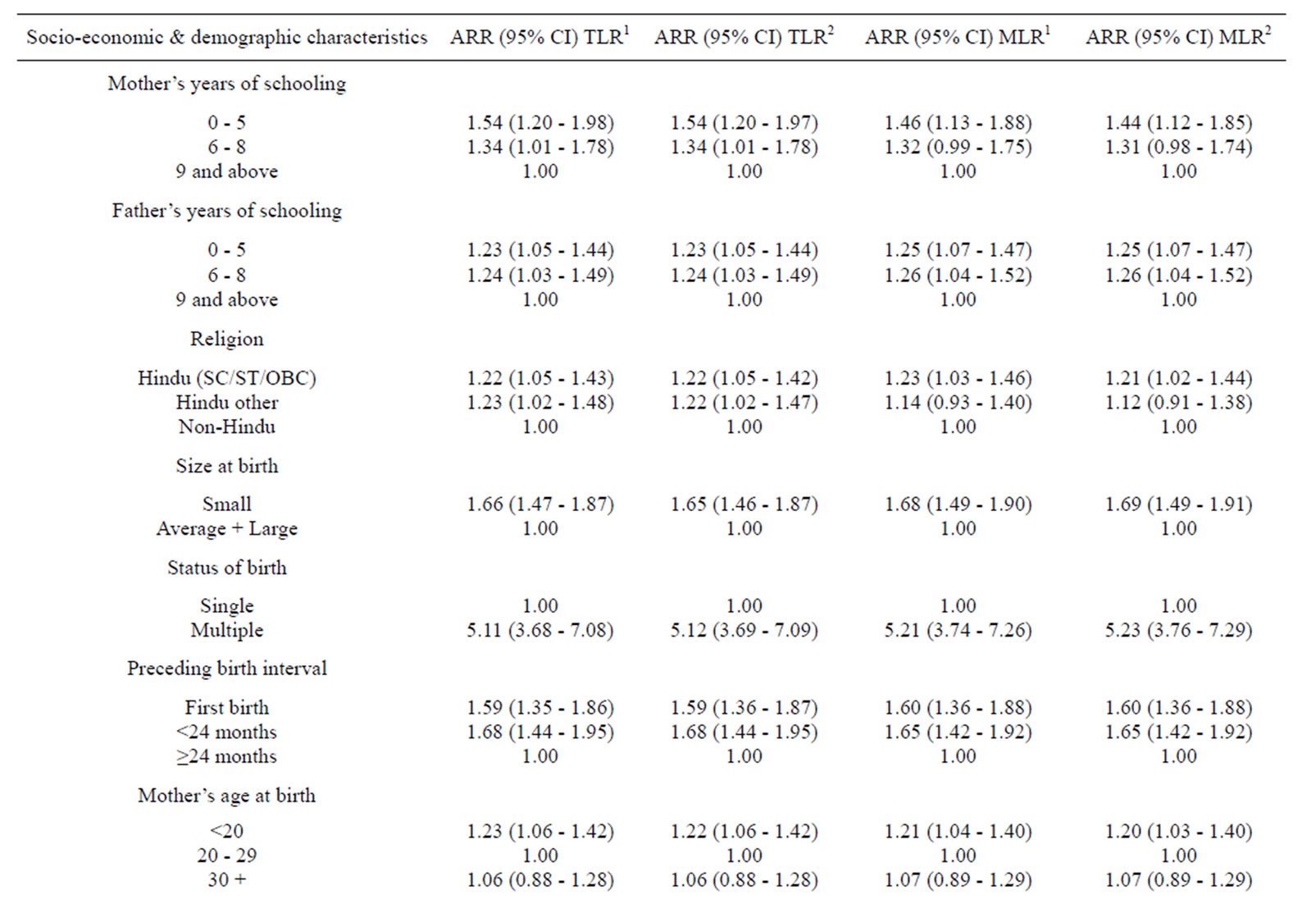
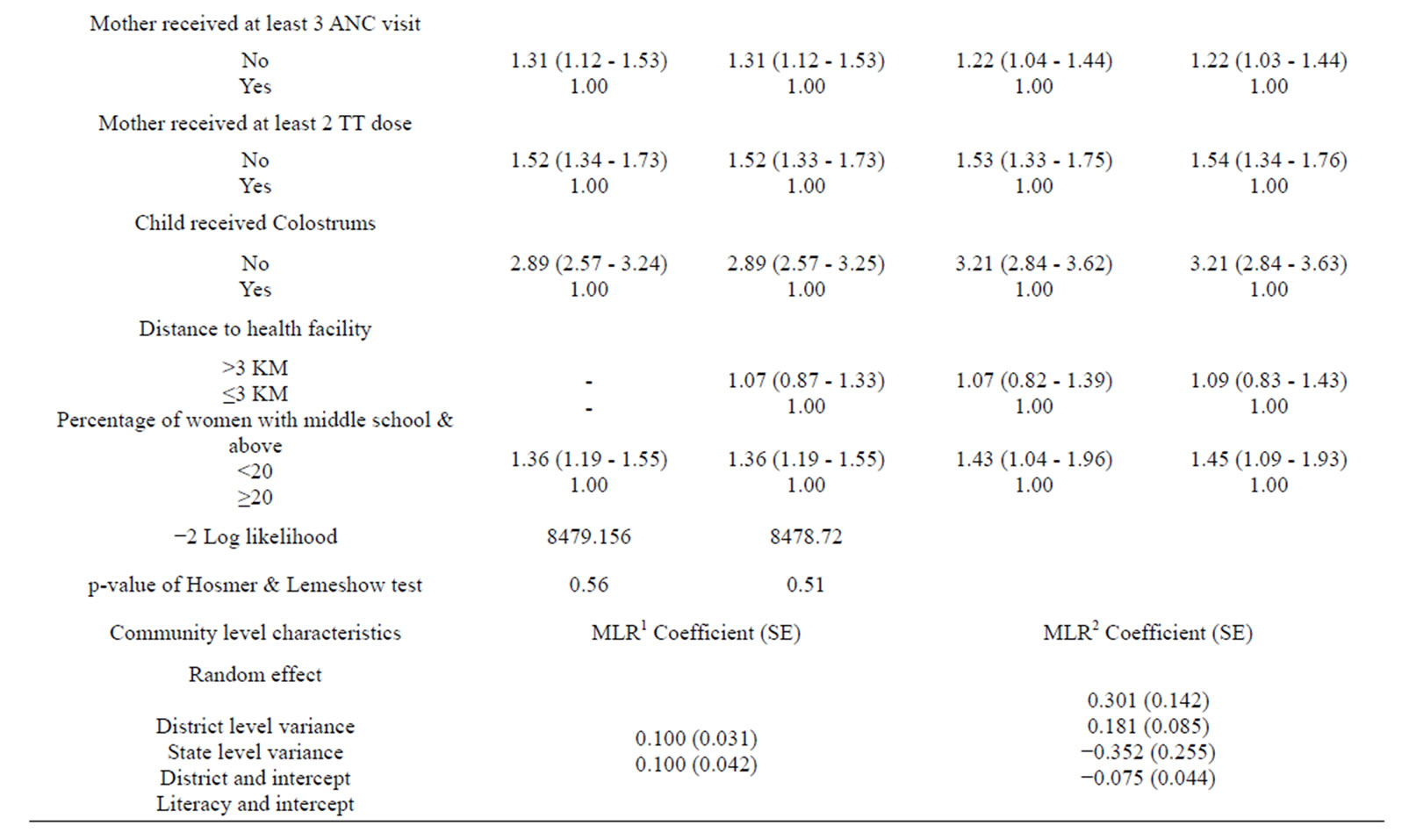
Table 2. Adjusted risk ratio (ARR) and corresponding 95% confidence interval (95% CI) for the infant death in Rural India by socio economic and demographic characteristics using traditional (TLR) and multilevel logistic regression (MLR) analysis.
The children belonging to district having health facilities beyond 3 km had comparatively higher chance of dying during infancy, however not statistically significant [1.13 (0.92 -1.39)]. The children belonging to state with low level of awareness about ORS among women [1.61 (1.43 - 1.81)], low level of middle school and above literacy among the mothers’ [1.64 (1.45 - 1.85)], higher level of children with birth order 4 and above [1.61 (1.43 - 1.81)]; high level of any kind anemia among mothers [1.51 (1.30 - 1.75)] and low per capita expenditure on health [1.18 (1.05 - 1.33)] had comparatively higher chances to die before celebrating their first birthday.
As evident from Table 2, in general, the results under multilevel analysis (MLR1) and (MLR2) involve comparatively broader confidence interval in comparison to traditional logistic regression analysis (TLR2). The results related to data analysis from rural area provided almost similar results to those for overall India [1] other than few exceptions. For example, the covariate namely complications during pregnancy did not enter in the model at all. Further, among community level covariates, % of woman with any anemia also did not enter in the model. However, the additional covariate considered at district level in Rural India data, namely distance to health facilities, entered in the model.
The results under random intercept model for rural India reconfirm the findings obtained at national level [1]. Further, they indicate that even after consideration of these covariates, variation in infant mortality remains significant not only between States but also between Districts. Such genuine exploration is not possible under TLR2. Again, the results under random coefficient models reconfirm the findings observed at national level [1]. Further, as an additional observation, the probability of infant mortality is high in rural areas of districts having health facility beyond three kilometers than their counterparts.
Under the above model, the probability of infant mortality was allowed to vary across States, however, the effects of the explanatory variables were assumed to be same for each State. Under random coefficient model (MLR2), as a modification in this assumption, the coefficients related to % of women with middle education & above and % of women with any anemia were also assumed to vary across the States. The results indicate that the effect of % of women with middle school and above ranging from 12% to 56% does indeed vary across States [28]. As obvious, the results further indicate that State level variation in the probability of infant mortality is higher in communities having low % of women with middle school and above than their counterparts. Likewise, State level variation in the probability of infant mortality is likely to be higher in communities having high % of women with any anemia ranging from 23% to 70% [28] than their counterparts.
4. DISCUSSION
As reported earlier for overall India [1], in rural India also, those children are more likely to die before celebrating their first birthday; whose mothers have comparatively lower education; do not have exposure to mass media; fathers also have a low level of education; who belong to SC/ST/OBC categories, low and medium standard of living index; birth order is the first; whose size at birth is small; who are multiple at birth; who are either first birth or born before 24 months of previous child; whose mothers are youngsters below 20 years of age; whose mothers do not receive three ANC visits for check-up; and also do not receive two TT dose; whose mothers could not consume all given iron tablets during pregnancy; whose mothers deliver the child at non-institutional place; and who do not receive colostrums [13- 24].
As expected, multilevel analysis revealed comparatively broader confidence interval in comparison to traditional logistic regression analysis [26,27]. Other than few exceptions, the results under multilevel analysis of data from rural area provided almost similar results to those for overall India [1]. At individual level, the covariate namely complications during pregnancy did not enter in the model at all. Further, among state level covariates, contrary to % of women with middle school and above, % of woman with any anemia did not enter in the model. However, the additional covariate considered at district level in Rural India data, namely distance to health facilities, entered in the model. Further, they indicate that even after consideration of these covariates, variation in infant mortality remains significant not only between States but also between Districts. As an additional observation, the probability of infant mortality is high in rural areas of districts having health facility beyond three kilometers than their counterparts.
In summary, state/district level developmental indicators are likely to still vary significantly across the states/ districts and also their effects on infant mortality. Hence, for further improvements, there is a need to focus on district level planning as well instead of only at the state level. Taking into account the findings under the present study, for a data involving hierarchical structure, there is a need to emphasize the use of the possible highest levels in hierarchical models (i.e., multilevel models) instead of compromising with lower level models. To further emphasize, such optimal considerations may provide additional important clues to policy planners leading to optimal use of available resources regarding public health programs.
5. ACKNOWLEDGEMENTS
The Indian Council of Medical Research is duly acknowledged to support this methodological research as a Task Force Project in Statistics. Further, the All India Institute of Medical Sciences, New Delhi, is also acknowledged for extending needful timely support in all respects.
REFERENCES
- Dwivedi, S.N., Begum, S., Dwivedi, A.K. and Pandey, A. (2012) Community effects on public health in India: A hierarchical model. Health, 4, 526-536.
- Mosley, W.H. (1984) Child survival: Research and policy. Population and Development Review, 10, 3-23. http://dx.doi.org/10.2307/2807953
- Nath Dilip, C., Kenneth, C.L. and Talukdar, P.K. (1994) Most recent birth interval in a traditional society: A life table and hazards regression analysis. Canadian Studies in Population, 21, 149-164.
- Bryk, A.S. and Raudenbush, S.W. (1992) Hierarchical linear models (applications and data analysis methods). Sage Publications, Thousand Oaks.
- Goldstein, H. and Healy, M.J.R. (1995) The graphical presentation of a collection of means. Journal of the Royal Statistical Society Series A, 158, 175-177.
- Kalbfleisch, J.D. and Prentice, R.L. (1980) The statistical analysis of failure time data. John Wiley and Sons, New York.
- Cox, D.R. (1972) Regression models and life tables (with discussion). Journal of Royal Statistical Society, B34, 187-220.
- Menken, J., Trussel, J., Stempel, D. and Bahakol, O. (1981) Proportional hazard life table models: An illustrative analysis of socio-economic influences on marriage dissolution in the United States. Demography, 18, 181-200. http://dx.doi.org/10.2307/2061092
- Retherford, R.D. and Minja, K.C. (1993) Statistical models for casual analysis. John Wiley & Sons, Inc., New York.
- Trussell, J. and Charles, H. (1983) A hazards model analysis of the covariates of infant and child mortality in Sri Lanka. Demography, 20, 1-24. http://dx.doi.org/10.2307/2060898
- Namboodiri, N.K. and Suchindran, C.M. (1987) Life table techniques and their applications. Academic Press, Orlando.
- Kleinbaum, D.G. (1996) Survival analysis. Statistics in health sciences. Springer-Verlag, New York.
- Nath, D.C., Land, K.C. and Singh, K.K. (1994) Birth spacing, breastfeeding, and early child mortality in a traditional Indian society: A hazard model analysis. Social Biology, 41, 168-180.
- Hobcraft, J.J., McDonald, W. and Rustien, S. (1983) Childspacing effects on infant and early child mortality. Population Index, 49, 585-618. http://dx.doi.org/10.2307/2737284
- Maine, D. and McNamara, R. (1985) Birth spacing and child survival. Center for Population and Family Health, School of Public Health, Faculty of Medicine, Columbia University, New York.
- Khorshed, A.B.M., Alam, M. and James, F.P. (1990) A multivariate analysis of social and economic determinants of neonatal and infant mortality in four rural thanas of Bangladesh. Demography India, 19, 167-182.
- Swenson, I.E., Nguyen, M.T., Pham, B.S., Vu, Q.N. and Vu, D.M. (1993) Factors influencing infant mortality in Vietnam. Journal of Biosocial Science, 25, 285-302. http://dx.doi.org/10.1017/S0021932000020630
- Bloland, P., Slutsker, L., Steketee, R.W., Wirima, J.J., Heymann, D.L. and Breman, J.G. (1996) Rates and risk factors for mortality during the first two years of life in rural Malawi. American Journal of Tropical Medicine Hygen, 55, 82-86.
- Koeing, M.A., Phillips, J.A., Campbell, O. and D’Souza, D. (1990) Birth intervals and childhood mortality in rural Bangladesh. Demography, 27, 251-265. http://dx.doi.org/10.2307/2061452
- Miller, J.E., Trussell, J., Anne, R.P. and Barbara, V. (1992) Birth spacing and child mortality in Bangladesh and the Philippines. Demography, 29, 305-316. http://dx.doi.org/10.2307/2061733
- Mturi, A.J. and Curtis, S.L. (1995) The determinants of infant and child mortality in Tanzania. Health Policy Plan, 10, 384-394. http://dx.doi.org/10.1093/heapol/10.4.384
- Manda, S.O. (1999) Birth intervals, breastfeeding and determinants of childhood mortality in Malawi. Social Science Medicine, 48, 301-312. http://dx.doi.org/10.1016/S0277-9536(98)00359-1
- Chaudhary, S.B., Ibrahim, K.R. and Md. A.M. (2000) Impact of some biosocial variables on infant and child mortality. Demography India, 29, 211-221.
- Pandey, A., Minja, K.C., Norman, Y.L., Damodar, S. and Jagdish, C. (1998) Infant and child mortality in India. National Family Health Survey Subject Reports No. 11, IIPS, Bombay and East West Centre Program on Population, Honolulu, Hawaii.
- Arnold, F., Minja, K.C. and Roy, T.K. (1998) Son preference, the family-building process and child mortality in Inida. Population Studies, 52, 301-315. http://dx.doi.org/10.1080/0032472031000150486
- Dwivedi, S.N. and Sundaram, K.R. (2000) Epidemiological models and related simulation results for understanding of contraceptive adoption in India. International Journal of Epidemiology, 29, 300-307. http://dx.doi.org/10.1093/ije/29.2.300
- Steele, F., Diamond, I. and Wang. D.L. (1996) The determinants of contraceptive use in China: A multilevel multinomial discrete hazards modelling approach. Demography, 33, 12-24. http://dx.doi.org/10.2307/2061710
- NFHS-2 (2000) National Family Health Survey (NFHS- 2), 1998-99, Final Report. International Institute for Population Sciences, Mumbai.
ABBREVIATIONS
AIIMS: All India Institute of Medical Sciences IMR: Infant Mortality Rate NFHS: National Family Health Survey SC-ST-OBC: Scheduled Caste-Scheduled Tribe-Other Backward Castes CI: Confidence Interval TLR1: Traditional Stepwise Logistic Regression without Consideration of District Level Variable TLR2: Traditional Stepwise Logistic Regression with Consideration of District Level Variable MLR1: Multilevel Logistic Regression as Random Intercept Model MLR2: Multilevel Logistic Regression as Random Intercept as well as Slope Model IGLS: Iterative Generalized Least Squares MQL: Marginal Quasi Likelihood PQL: Partial Quasi Likelihood STATA: Data Analysis and Statistical Software SPSS: Statistical Package for the Social Sciences