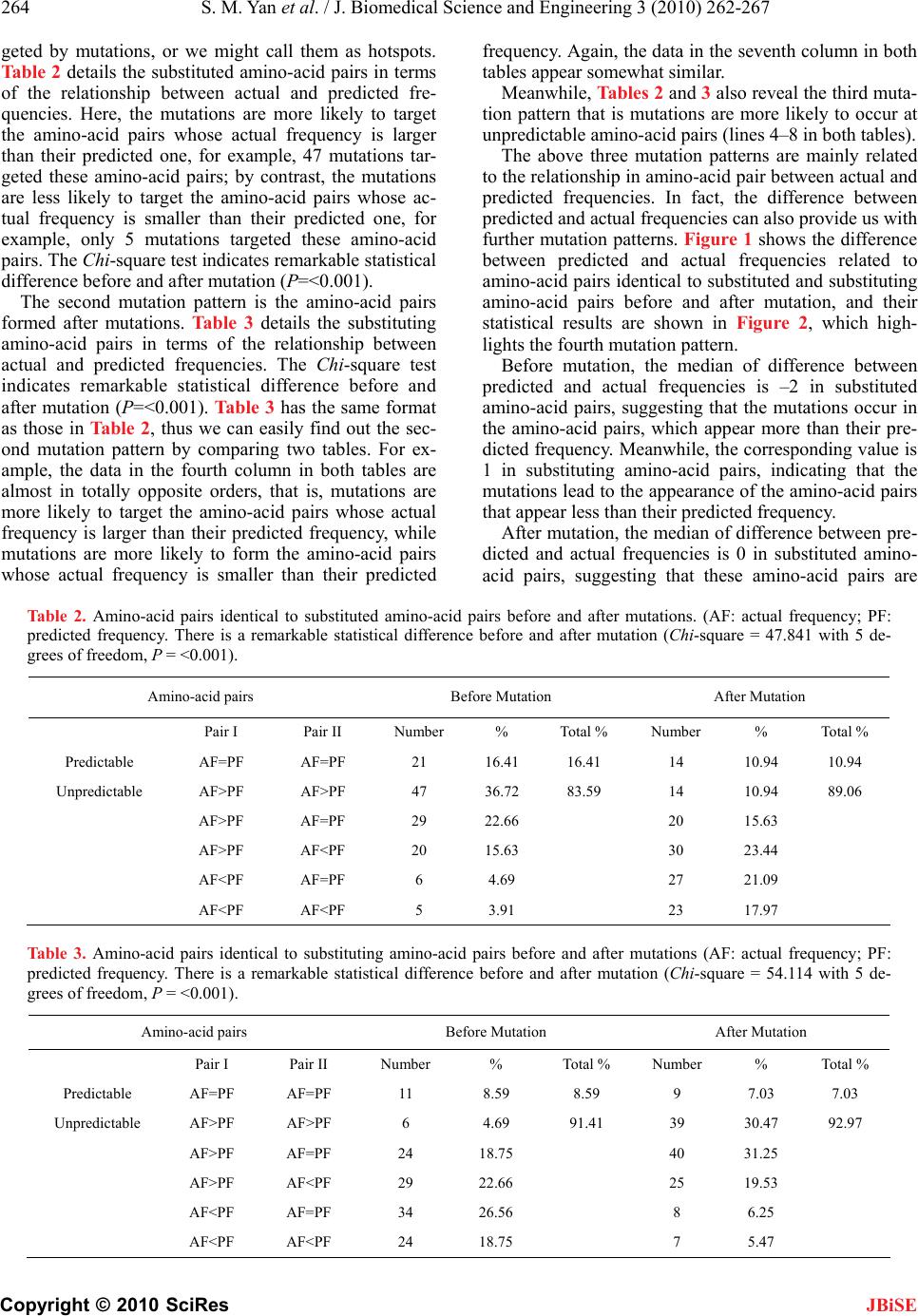
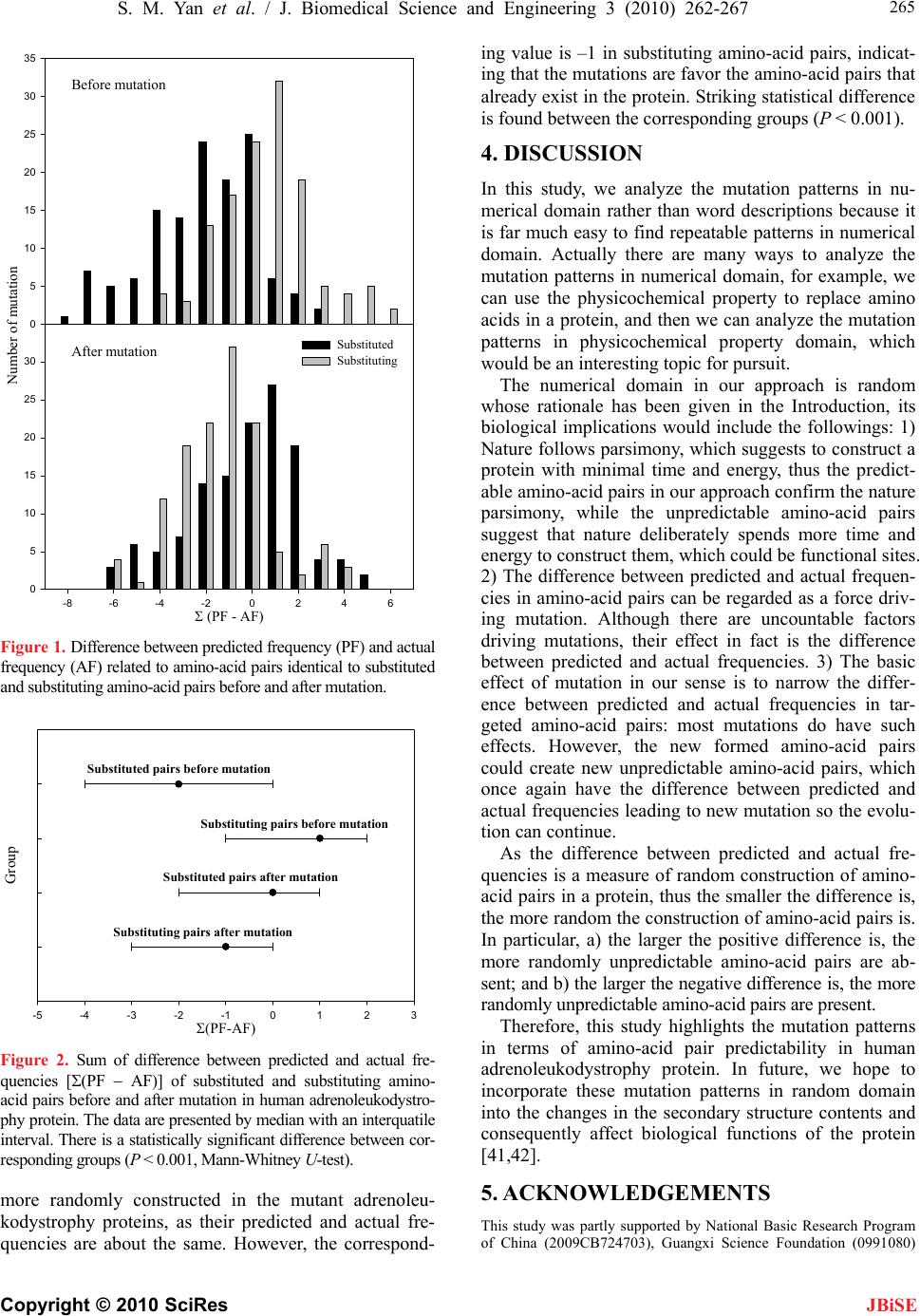
266 S. M. Yan et al. / J. Biomedical Science and Engineering 3 (2010) 262-267
Copyright © 2010 SciRes JBiSE
and Guangxi Academy of Sciences (09YJ17SW07).
REFERENCES
[1] Rideout, W.M., Coetzee, G.A., Olumi, A.F. and Jones,
P.A. (1990) 5-Methylcytosine as an endogenous mutagen
in human LL receptor and p53 genes. Science, 249,
1288-1290.
[2] Montesano, R., Hainaut, P. and Wild, C.P. (1997) Hepa-
tocellular carcinoma: From gene to public health. Jour-
nal of the National Cancer Institute, 89, 1844-1851.
[3] Hainaut, P. and Pfeifer, G.P. (2001) Patterns of p53 GT
transversions in lung cancers reflect the primary mutagenic
signature of DNA-damage by tobacco smoke. Carcino-
genesis, 22, 367-374.
[4] Fasman, G.D. (1976) Handbook of biochemistry: Section
D physical chemical data. 3rd Edition, CRC Press, Lon-
don and New York.
[5] Wu, G., and Yan, S. (2002) Randomness in the primary
structure of protein: methods and implications. Molecu-
lar Biology Today, 3, 55-69.
[6] Wu, G. and Yan, S. (2006) Mutation trend of hemaggluti-
nin of influenza A virus: A review from computational
mutation viewpoint. Acta Pharmacologica Sinica, 27,
513-526.
[7] Wu, G. and Yan, S. (2006) Fate of influenza A virus pro-
teins. Protein and Peptide Letters, 13, 377-384.
[8] Wu, G. and Yan, S. (2008) Lecture Notes on Computa-
tional Mutation. Nova Science Publishers, New York.
[9] Everitt, B.S. (1999) Chance rules: An informal guide to
probability, risk, and statistics. Springer, New York.
[10] Efferth, T. (2001) The human ATP-binding cassette
transporter genes: From the bench to the bedside. Current
Molecular Medicine, 1, 45-65.
[11] Pohl, A., Devaux, P.F. and Herrmann, A. (2005) Function
of prokaryotic and eukaryotic ABC proteins in lipid
transport. Biochimica and Biophysica Acta, 1733, 29-52.
[12] Oswald, C., Holland, I.B. and Schmitt, L. (2006) The
motor domains of ABC-transporters. What can structures
tell us? Naunyn-Schmiedeberg's Archives of Pharmacol-
ogy, 372, 385-399.
[13] Kim, J.H. and Kim, H.J. (2005) Childhood X-linked
adrenoleukodystrophy: Clinical-pathologic overview and
MR imaging manifestations at initial evaluation and fol-
low-up. Radiographics, 25, 619-631.
[14] Shimozawa, N. (2007) Molecular and clinical aspects of
peroxisomal diseases. Journal of inherited metabolic dis-
ease, 30, 193-197.
[15] Wanders, R.J., Visser, W.F., van Roermund, S., Kemp,
C.W. and Waterham, H.R. (2007) The peroxisomal ABC
transporter family. Pflügers Archiv European Journal of
Physiology, 453, 719-734.
[16] Moser, H., Dubey, P. and Fatemi, A. (2004) Progress in
X-linked adrenoleukodystrophy. Current opinion in neu-
rology, 17, 263-269.
[17] Moser, H.W., Mahmood, A. and Raymond, G.V. (2007)
X-linked adrenoleukodystrophy. Nature Clinical Practice.
Neurology, 3, 140-151.
[18] Wanders, R.J. and Waterham, H.R. (2005) Peroxisomal
disorders I: Biochemistry and genetics of peroxisome
biogenesis disorders. Clinical Genetics, 67, 107-133.
[19] Bezman, L., Moser, A.B., Raymond, G.V., Rinaldo, P.,
Watkins, P.A., Smith, K.D., Kass, N.E. and Moser, H.W.
(2001) Adrenoleukodystrophy: Incidence, new mutation
rate, and results of extended family screening. Annals of
Neurol, 49, 512-517.
[20] Elgersma, Y. and Tabak, H.F. (1996) Proteins involved in
peroxisome biogenesis and functioning. Biochimica and
Biophysica Acta, 1286, 269-283.
[21] Hettema, E.H. and Tabak, H.F. (2000) Transport of fatty
acids and metabolites across the peroxisomal membrane.
Biochimica and Biophysica Acta, 1486, 18-27.
[22] Clayton, P.T. (2001) Clinical consequences of defects in
peroxisomal beta-oxidation. Biochemical Society Trans-
actions, 29, 298-305.
[23] Hargrove, J.L., Greenspan, P. and Hartle, D.K. (2004)
Nutritional significance and metabolism of very long
chain fatty alcohols and acids from dietary waxes. Ex-
perimental Biology and Medicine, 229, 215-226.
[24] Kemp, S. and Wanders, R.J. (2007) X-linked adrenoleu-
kodystrophy: Very long-chain fatty acid metabolism,
ABC half-transporters and the complicated route to
treatment. Molecular Genetics and Metabolism, 90,
268-276.
[25] Takano, H., Koike, R., Onodera, O. and Tsuji, S. (2000)
Mutational analysis of X-linked adrenoleukodystrophy
gene. Cell Biochemistry and Biophysics, 32, 177-185.
[26] Berger, J. and Gärtner, J. (2006) X-linked adrenoleukodys-
trophy: Clinical, biochemical and pathogenetic aspects.
Biochimica and Biophysica Acta, 1763, 1721- 1732.
[27] Kemp, S., Pujol, A., Waterham, H.R., van Geel, B.M.,
Boehm, C.D., Raymond, G.V., Cutting, G.R., Wanders,
R.J.A. and Moser, H.W. (2001) ABCD1 mutations and
the X-linked adrenoleukodystrophy mutation database:
Role in diagnosis and clinical correlations. Human Muta-
tion, 18, 499-515.
[28] Bairoch, A. and Apweiler, R. (2000) The SWISS-PROT
protein sequence data bank and its supplement TrEMBL
in 2000. Nucleic Acids Research, 28, 45-48.
[29] Wu, G. (1999) The first and second order Markov chain
analysis on amino acids sequence of human haemoglobin
-chain and its three variants with low O2 affinity. Com-
parative Haematology International, 9, 148-151.
[30] Wu, G. (2000) The first, second, third and fourth order
Markov chain analysis on amino acids sequence of hu-
man dopamine-hydroxylase. Molecular Psychiatry, 5,
448-451.
[31] Wu, G. and Yan, S.M. (2001) Prediction of presence and
absence of two- and three-amino-acid sequence of human
monoamine oxidase B from its amino acid composition
according to the random mechanism. Biomolecular En-
gineering, 18, 23-27.
[32] Wu, G. and Yan, S.M. (2002) Estimation of amino acid
pairs sensitive to variants in human phenylalanine hy-
droxylase protein by means of a random approach. Pep-
tides, 23, 2085-2090.
[33] Wu, G. and Yan, S. (2003) Determination of amino acid
pairs sensitive to variants in human-glucocerebrosidase
by means of a random approach. Protein Engineering
Design and Selection, 16, 195-199.
[34] Wu, G. and Yan, S. (2004) Fate of 130 hemagglutinins
from different influenza A viruses. Biochemical and Bio-
Physical Research Communications, 317, 917-924.